- July 29, 2020
- Posted by: Jyothishkumar Arumugam
- Category: Data engineering

Federated learning is a machine learning setting that enables multiple parties to jointly retrain a shared model without sharing the data among them. This has advantages in areas like increased intelligence scale and privacy.
In some plain English, this Federated Learning is the way of learning for machines without even seeing the data, so you don’t have to fear your privacy is being stolen for the sake of better service.
Decentralised Data and Intelligence
A large number of data nowadays are born in decentralised silos like mobile devices, IoT devices. Making a collective intelligence from this decentralised data in a traditional way and has always been a challenging one.
Why is it Challenging?
Traditionally the individual data sources will be transmitting the generated data to a centralised server and the machine learning algorithm will be trained on the collected data and the intelligence is now centralised. All the clients will be making some request calls to the central model along with the data, in order to unlock the hidden knowledge present in the data.
Check out our Machine Learning and Deep Learning Services
Read More
What is inherently challenging in this era of decentralised data is
- The sensitivity of the data
- High latency
The Sensitivity of the Data
The data which these isolated data generators are creating might inherit some of the user’s personal data, which they don’t want to share to the world even for any charitable reasons.
Example: A hospital will not share the patient data with any other organisation, a friend of yours won’t share his personal text messages with you
High Latency
Applications which need the low turnaround time cannot benefit from this model of intelligence, as this network calls bring along with them the high latency to unlock the intelligence.
Machine Learning in the Era of Decentralised System – Federated Learning
Federated Learning as like the term goes:
“A set up as a single centralized unit within which each state or division keeps some internal autonomy.”
Thus all the participants will be acting together as a group where each one of them is having its own rights to contribute and utilize, thus preserving the decentralised nature on a whole.
How Federated Learning Answers the challenges of Conventional Machine Learning
This Federated learning approach has major components like
Let us see in a stepwise manner how it works along with these components
- Initial Model
- Local Training on clients
- Encrypted communication of weights to the server
- Aggregation over Encrypted Values.
Initial Model
The model owners will be preparing the initial models and based on random initialization of the parameters
Local Training on Clients
Each client will be training the model on the set of data they have created. This training will not be for convergence and will be done for some iterations to capture the initial weights. At the time of training not every client device is made to train, the devices which satisfy several conditions will only be used for training.
As in the case of mobile devices they can participate only in training when they are plugged in a power source or when a wifi connection is made available.
Encrypted communication of weights to the Server
Once after the training is done the new weights will be communicated to the server for aggregation. The model weights are being encrypted before sending out to the servers.
Aggregation in the Server
The server does all the aggregation on the encrypted data and the new model is created as an aggregate of all the clients which are participants of the training process.
This cycle of to and fro communication and weight updates are being carried out in order to reach out a convergence at the server.
A practical Walkthrough in Tensorflow
Let us use this framework of federated Learning applied to train a deep neural network. Let us take the example of the MNIST data set and have a step by step process of creating the Federated model.
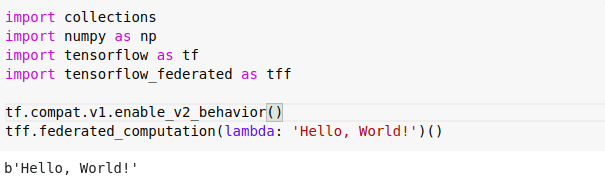
Step 1: Setting up the environment
Verify the environment is being set up in order to follow the tutorial. If you can see a welcome message you are good to follow

Step 2: Data Preparation and Client creation
Federated Learning requires data to be prepared in a federated format. In this tutorial since we are simulating the participants of our federated training, we are good to use the simulated dataset available along with TFF.
This simulated dataset is splitting the data and creating a virtual federated client around the data (accessible through client_id)
Load the data from TFF simulation and check the value types

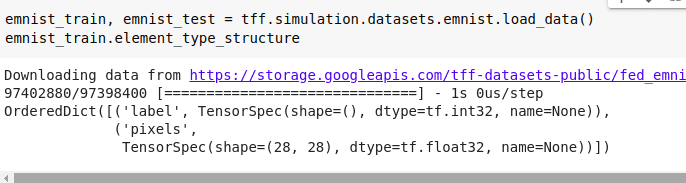
Thus we can see the data types are having the X and Y labels marked as ‘pixels’ and ‘labels’
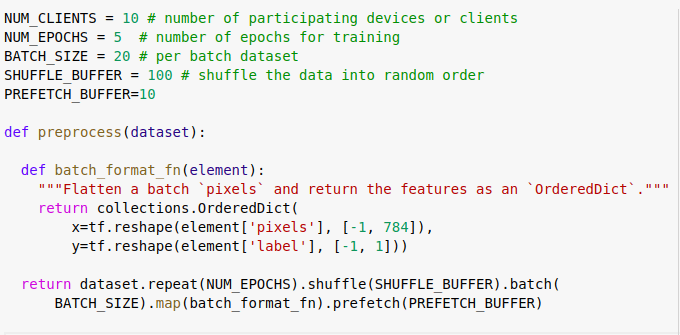
Let us prepare the dataset for making the flatten objects out of the images and prefetch the datasets for the next batch.

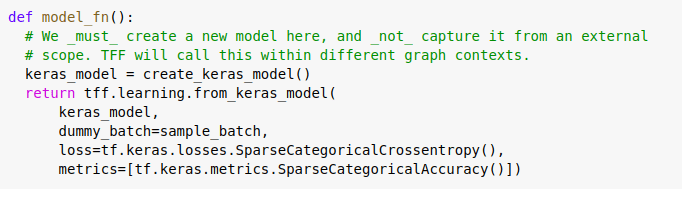
Step 3: Model Creation
We are creating a simple deep learning model with a single layer and a Softmax layer to classify the images.


This model function is our normal tensorflow model, in order to use the same for the federated learning purpose TFF provides a wrapper class which can take in the model and a dummy sample data to wrap it for our purpose.

Step 4: Training the federated Model
Training or the learning in a federated setup is done with the help of the tff.learning.build_federated_averaging_process function, which takes 3 parameters
- Model wrapped inside tff wrapper
- Client optimiser
- Server optimiser


Iterating over the data and aggregating on the server for several rounds of data will lead to better convergence of the data.
Leverge your Biggest Asset Data
Inquire Now
Let us run the same steps of iteration for over a period of 1000 iterations in the randomly sampled client devices leads to the improvised accuracy

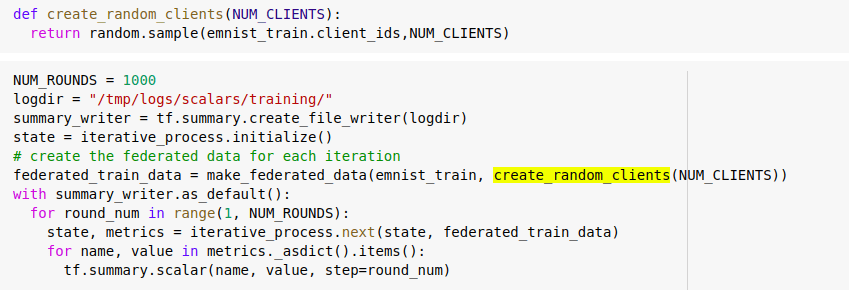
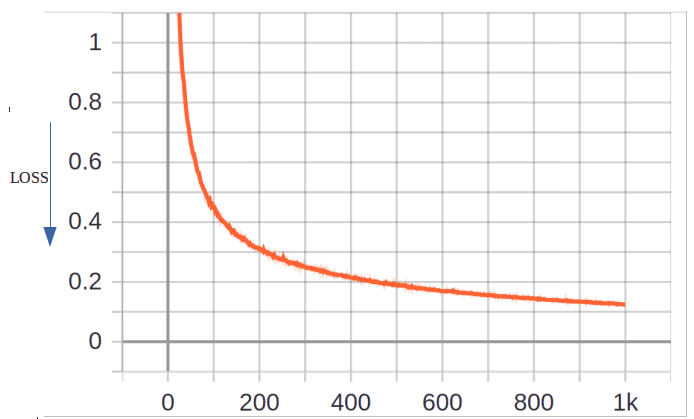
Logging the data capture across every training iterations and visualising over the tensorboard we can see the loss declining smoothly.
Results of the training can be seen in the graph.

Future Works:
With the highly changing landscape, the TensorFlow and federated learning have been rolling out a lot of updates every week. In the continuous weeks, we can see how can we use any pre-trained model in the federated learning setup. How to use the tensorflow_encrypted to carryout encrypted computation among other model types other than deep learning can be studied.