- May 17, 2023
- Posted by: Sintu kumar
- Category: Data & Analytics
Introduction
AI advancements are occurring more frequently now than ever before. ChatGPT, a fine-tuned version of GPT 3.5, is one of the hottest topics right now. One of the challenges of GPT is hallucination, which means It may generate a nonfactual response. In this blog, I will take you through a question-and-answer system (Q&A) based on our custom data, where we will try to overcome the hallucination problem using retrieval mechanisms.
Before building a Q&A system, let’s understand the theoretical aspects of “GPT and Hallucination”.
GPT is a deep neural network model based on the transformer architecture, a kind of attention-based model that makes use of self-attention to process sequential data, like text. Recently, GPT-4, a multimodal programme that can process text, images, and videos, was released. The transformer decoder block is the foundation of the GPT architecture.
The general concept behind GPT was to pre-train the model on unlabeled text from the internet before fine-tuning it with labelled data for tasks.
Let’s examine pre-training on unsupervised data in more detail. Maximizing the log conditional probability of a token given previous tokens is the goal here. According to the GPT paper [1]
 We can fine-tune it for different tasks on supervised data after pre-training.
We can fine-tune it for different tasks on supervised data after pre-training.
Hallucination
The term “hallucination” refers to an LLM response that, despite having a good syntactical appearance, contains incorrect information based on the available data. Hallucination simply means that it is not a factual response. Because of this significant issue with these LLMs, we cannot completely rely on the generated response.
Let’s use an example to better understand this.
 Here, when I ask ChatGPT a question about Dolly, it gives me a hallucinatory answer. Why? Since it was trained on a sizeable body of data, it does its best to mimic the response.
Here, when I ask ChatGPT a question about Dolly, it gives me a hallucinatory answer. Why? Since it was trained on a sizeable body of data, it does its best to mimic the response.
Below is the appropriate response to Dolly from the DatabricksLab GitHub page.

Also Read: Generative AI: Scope, Risks, and Future Potential
Reduce Hallucinations by:
- Taking low temperature parameter values
- Chain of thought prompting
- Agents for sub task (can use lang chain library)
- Use context injection and prompt engineering
Use Case
Using GPT and BERT (Bidirectional Encoder Representations from Transformers), let’s build a Q&A on a custom dataset. To find the context for each user’s question semantically, I’m using BERT in this situation. You can query custom data found in various documents, and the model will respond.
GPT can be used in two different ways to meet specific requirements:
1. Context Injection
2. GPT’s fine-tuning
Let’s take them in turn.
Context Injection
Here, the plan is to send context along with the text completion query to GPT, who will then use that information to generate a response. Using BERT and the corresponding document text corpus, we will locate the context for each question.
Architecture
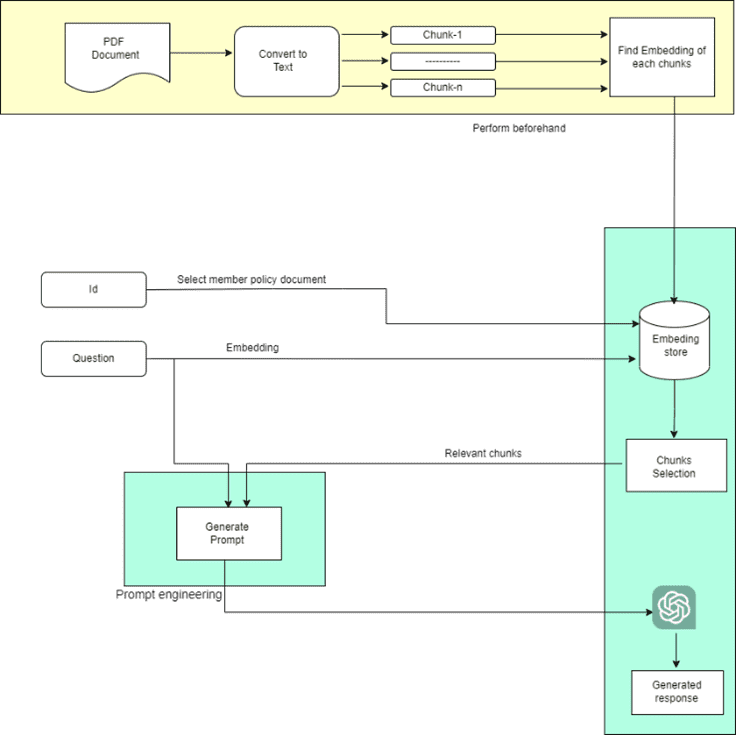
Now let’s examine the architecture
- Read each PDF file individually first, then break up the content into smaller sections.
- Locate and save the embeddings for each chunk. (Vector databases can be used for quick querying.).
- Accept the user’s question and ID as input.
- Using the input ID, choose the correct PDF. Locate the question’s embedding and semantically extract pertinent text from the PDF.
- Use the input question and pertinent text passages to create the prompt.
- Get the response by sending the prompt to GPT.
Now let’s proceed step by step with the code:
There are many methods for embedding, such as the open-source, pre-trained BERT family model and the paid OpenAI embedding api. I’ll be using hugging face’s open source embedding here.
Code
Import necessary libraries:


Here, I’m storing the embedding and metadata using a pinecone vector database. You can also use any other vector databases (some of open-source vector database are Weaviate < https://weaviate.io/ >, Milvus < https://milvus.io/ >)
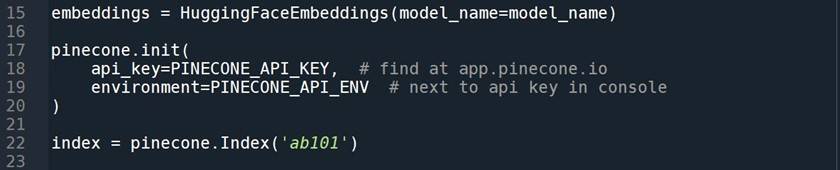
Let’s get all the api keys:


Let’s now set up the database and the pre-trained embedding model:
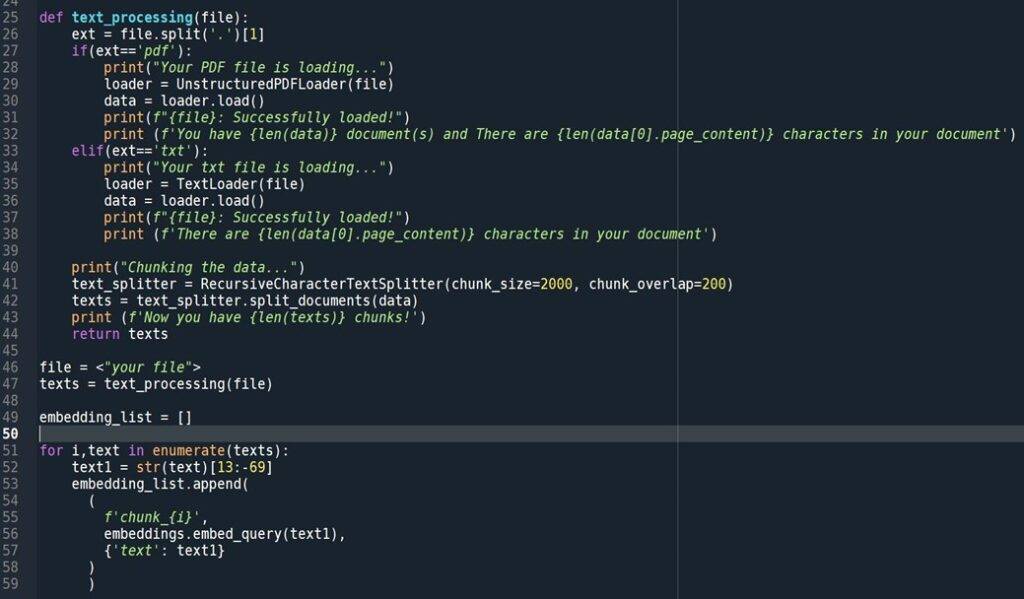
Let’s read the PDF/TXT document now. In order to find the embedding for each chunk, we will first chunk the content.
Read the file:
Save the embedding with metadata:
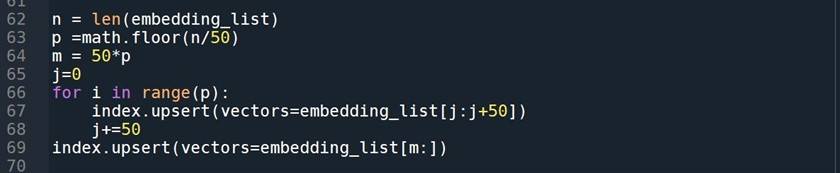
Now that we have embeddings for every document, let’s find out the context for a particular user question that was prompted by the GPT.
Get context:
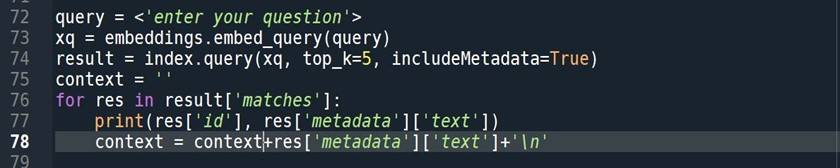
Finally, let’s proceed. To get the response, create a prompt and send it to the openAI completion api.
GPT response:


Voila…
GPT fine-tuning
In this use-case, fine-tuning is not recommended. Even so, there are numerous use cases where fine tuning will work fantastically, such as text classification and email pattern.
To fine-tune, first create the data in the format listed below.

Here, “prompt” refers to your query and context. The ideal response to the relevant question is considered complete. Make a few hundred data points, then execute the command below.
Use the below command for Data preparation.

Fine tune a particular model using the command below.


*If you are getting api_key error then add –api-key <’your api key’> after openai in the above command.
Python code that utilizes your refined model:

Check more on fine tuning by Open ai – https://platform.openai.com/docs/guides/fine-tuning
Unleash the full potential of your data with our advanced data and analytics services. Get started today!
Click here
Conclusion
A potent large language model with the potential to revolutionise NLP is the GPT family. We’ve seen a Q&A use-case based on our unique dataset where I used the context of the prompt to get around the GPT response’s hallucination issue.
We can use GPT to save time and money in a variety of use-cases. Additionally, the enhanced version of GPT (ChatGPT) has a wide range of applications, including the ability to create various plugins using various datasets and create chatbots using our own dataset. Continue looking into the various use-cases.