


- May 5, 2023
- Posted by: Surya Ashokan
- Category: Data & Analytics

Step-by-Step Guide to Scanned Bank Statement Data Extraction with TrOcr in Python
Now let’s dive into the step-by-step guide on how to use TROCR for scanned bank statement data extraction in Python. Here’s an overview of the process:
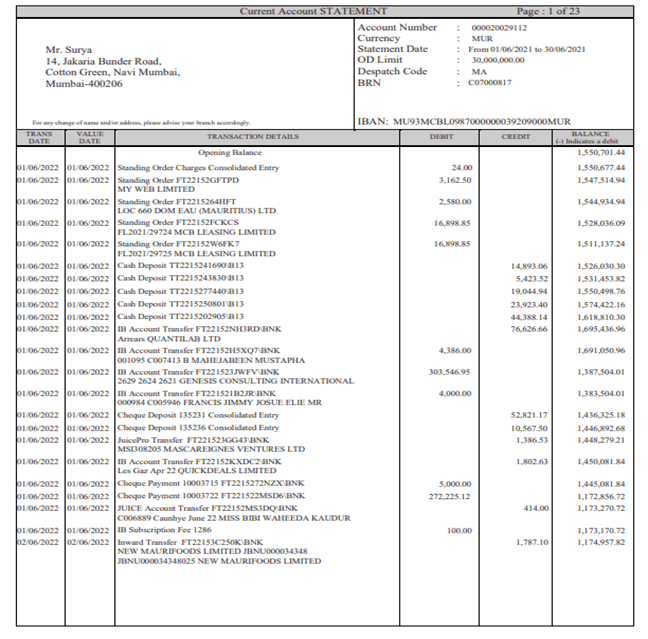
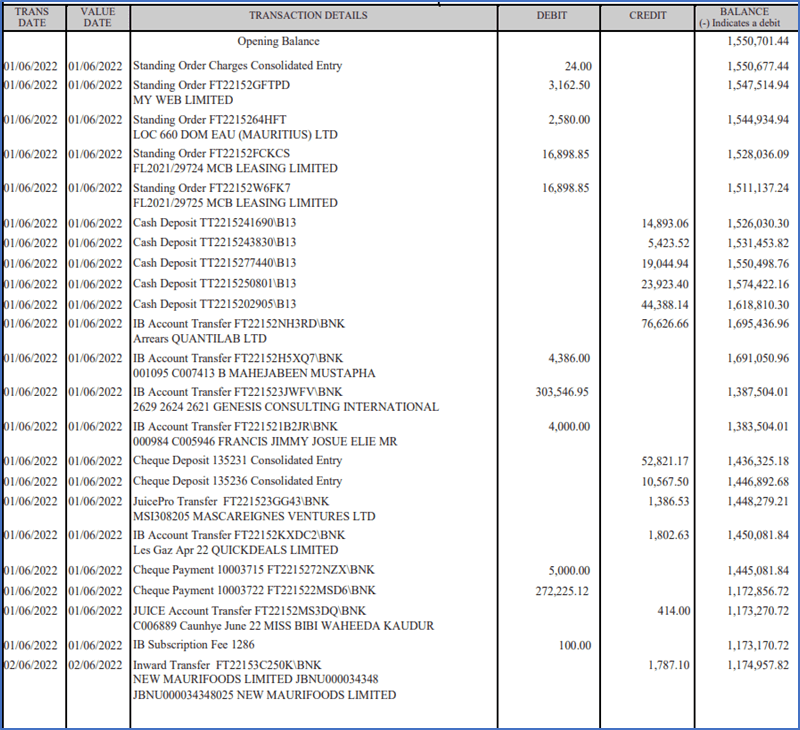
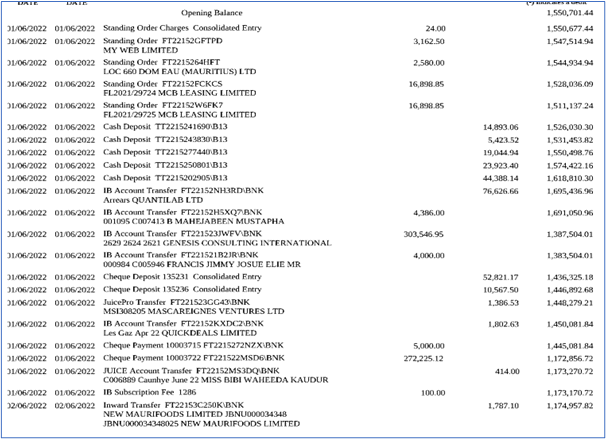
Sample digital bank document:
 Step 1: Convert PDF to Image Files
Step 1: Convert PDF to Image Files
There are several Python libraries that can be used for this, including PyPDF2 and pdf2image.

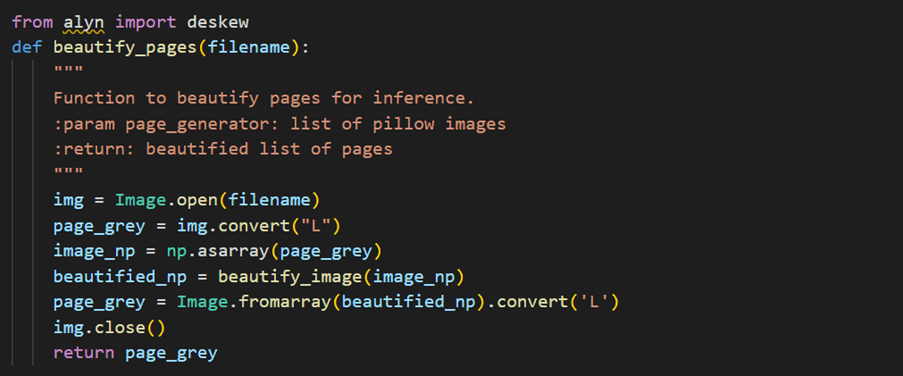
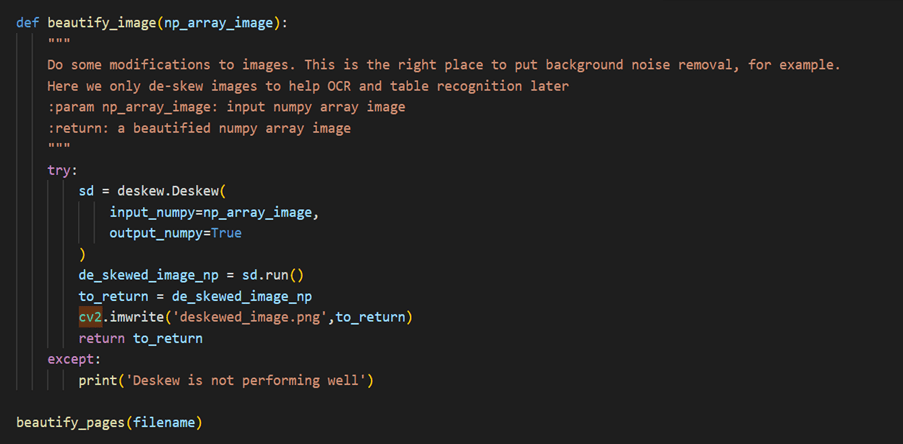
Step 2: Deskewing
Deskewing is a process that involves straightening an image that has been scanned or photographed at an angle. This is often necessary to improve the accuracy of image processing algorithms, such as OCR (optical character recognition), that rely on horizontal and vertical lines.

Step 3: Steps for Creating a Custom Model using Detectron2
- Steps for Creating a Custom Model using Detectron2:
- Dataset Preparation: The first step in creating a custom model using Detectron2 is to prepare the dataset. This involves gathering and labeling images, creating annotations, and converting the annotations to the COCO format. Detectron2 supports several dataset formats, including COCO, Pascal VOC, and Labelbox.
- Model Configuration: Once the dataset is prepared, the next step is to configure the model. Detectron2 provides a variety of pre-trained models that can be used as a starting point for custom models. You can also create your own model architecture using the modular design of Detectron2. This involves defining the backbone network, the feature pyramid network, the region proposal network, and the ROI (Region of Interest) head.
- Training the Model: After the model is configured, the next step is to train it using the prepared dataset. Detectron2 provides several training options, including the number of iterations, learning rate, and batch size. During the training process, you can monitor the progress of the model using the TensorBoard visualization tool.
- Evaluating the Model: Once the model is trained, the next step is to evaluate its performance. This involves testing the model on a separate validation dataset and calculating metrics such as mean average precision (MAP) and intersection over union (IoU). Detectron2 provides several evaluation tools for this purpose, including the COCO API and the built-in evaluation functions.
2. After creating the custom model, we need to provide input data in the correct format and use the model to generate output. This involves passing the input data through the model and obtaining the predicted bounding boxes and labels. You can use the Detectron2 API to perform this step.
3. Once we have the predicted bounding boxes, we must apply them to the original, scanned bank statement to produce the cropped images.
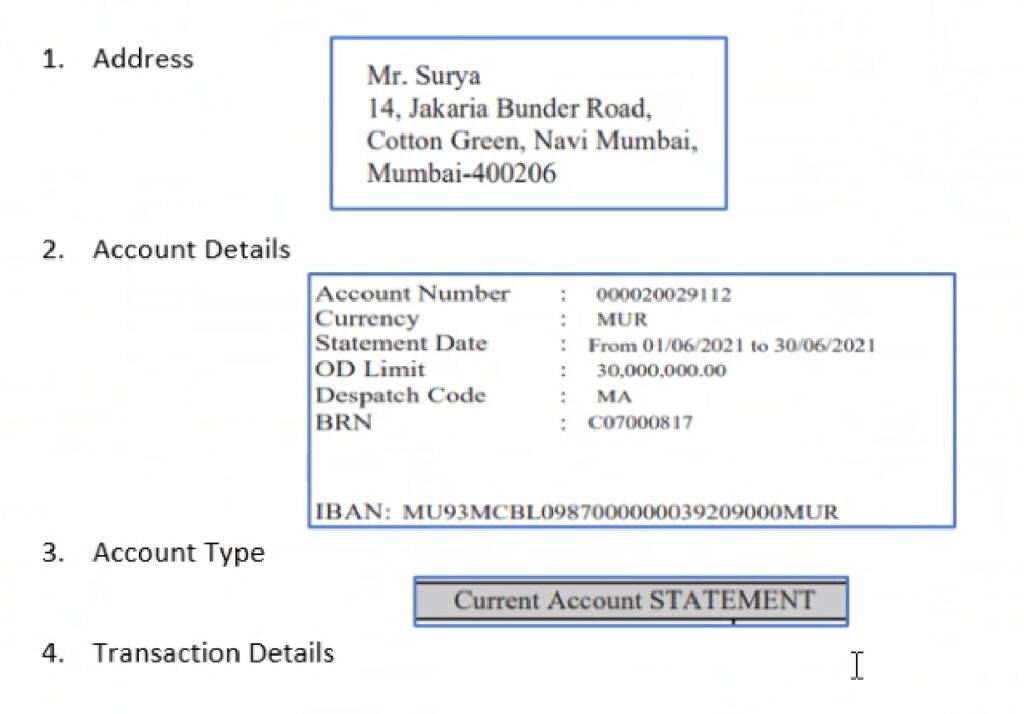

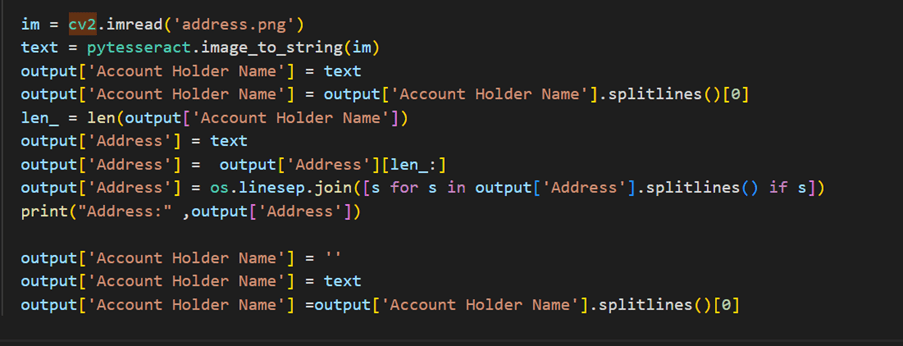
Step 4: Extracting Address, Account Details and Account Type
We can use PyTesseract to convert an image to text in Python. We will pass address image, account detail image and account type image one by one to PyTesseract.
1. Extracting Address and Account Holder Name:

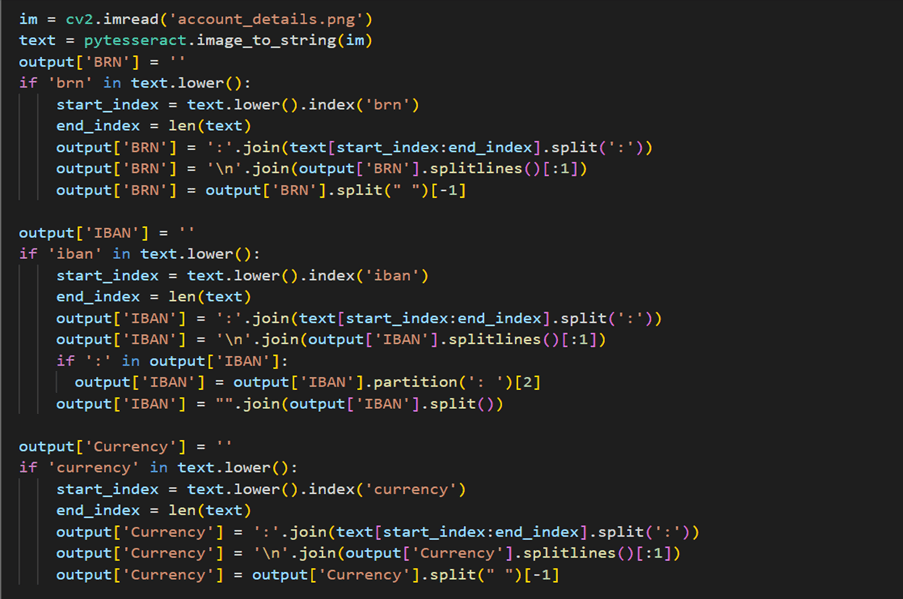
2. Extracting Account Details:
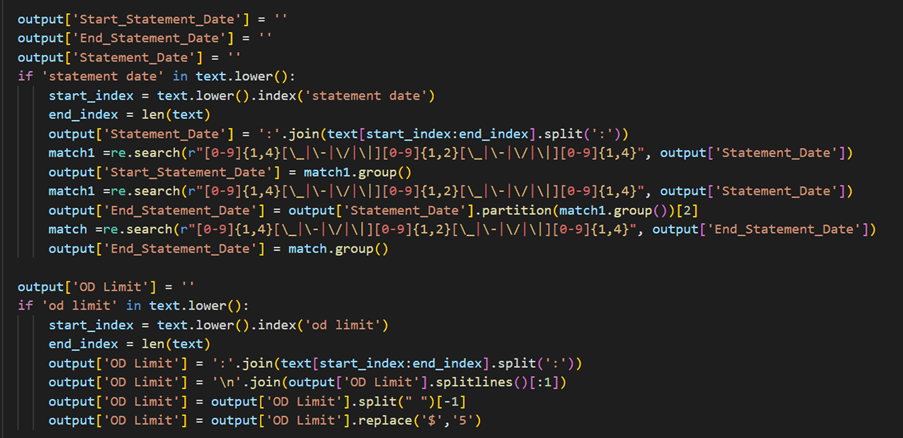
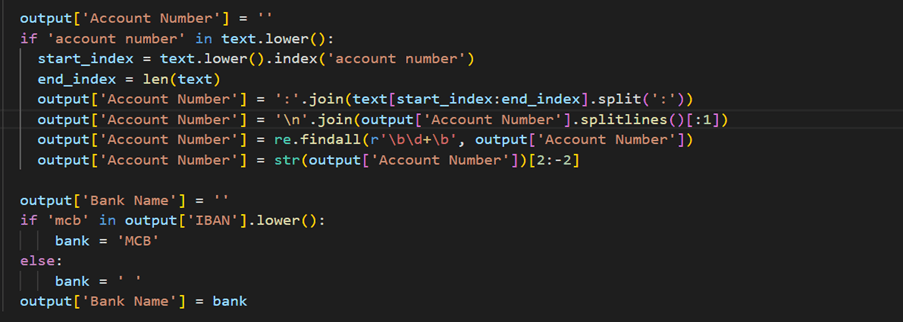

3. Extracting Account Type

4. Convert all the lists into DataFrame

5. Output CSV file
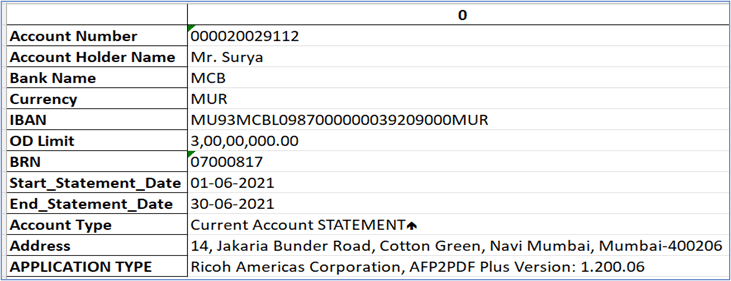
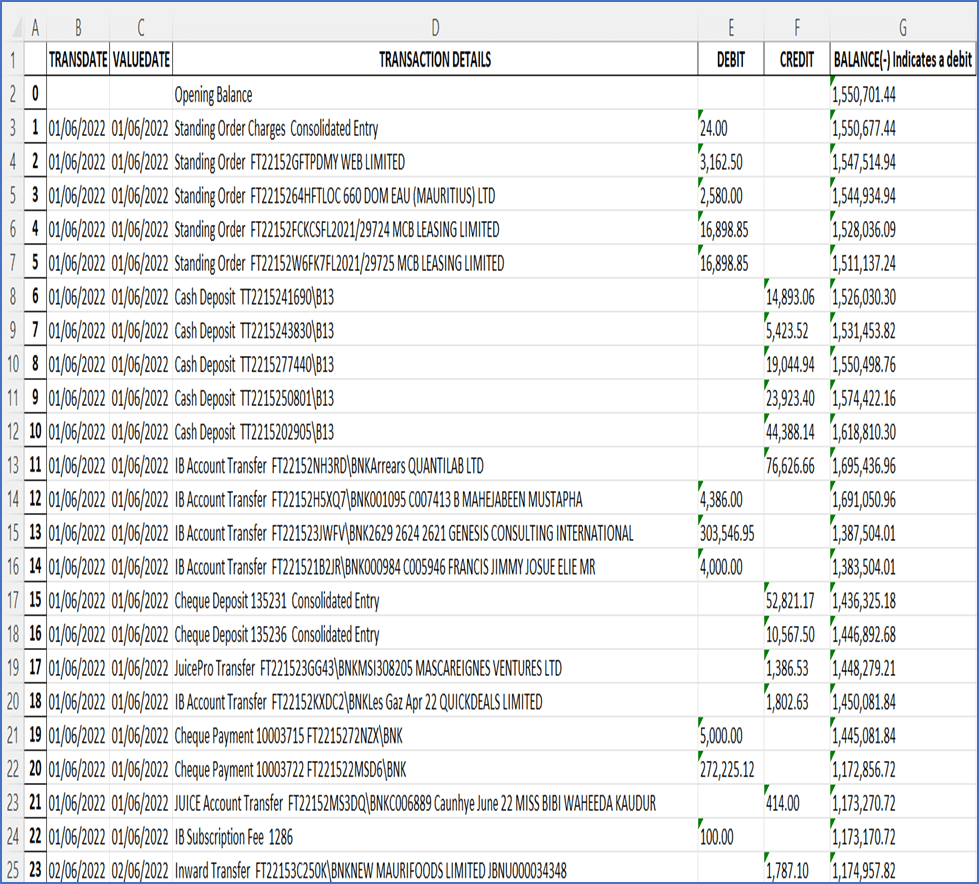
Step 5: Extracting Transaction Details
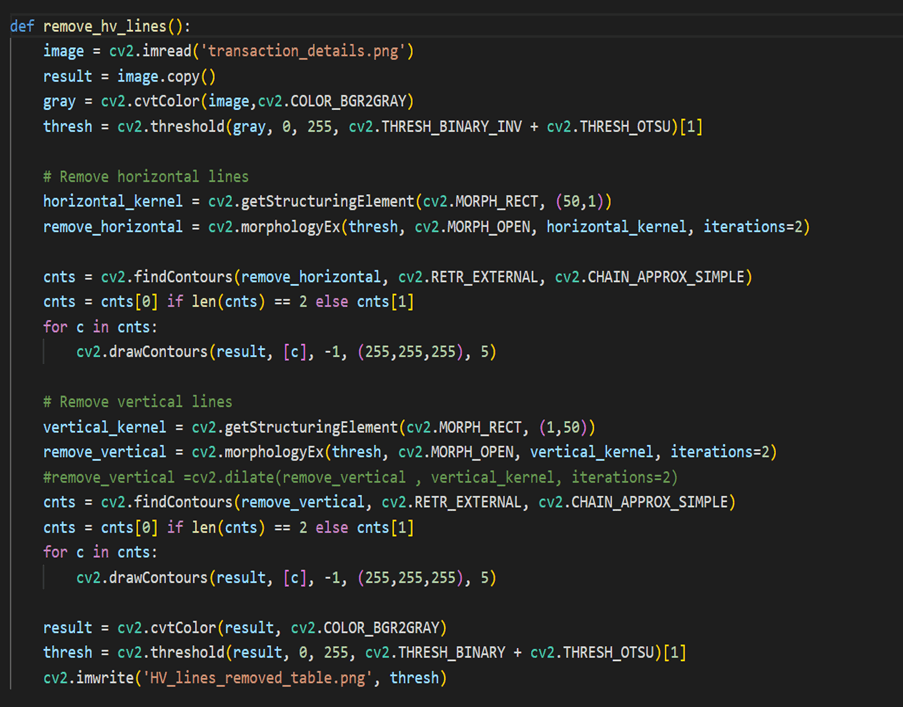
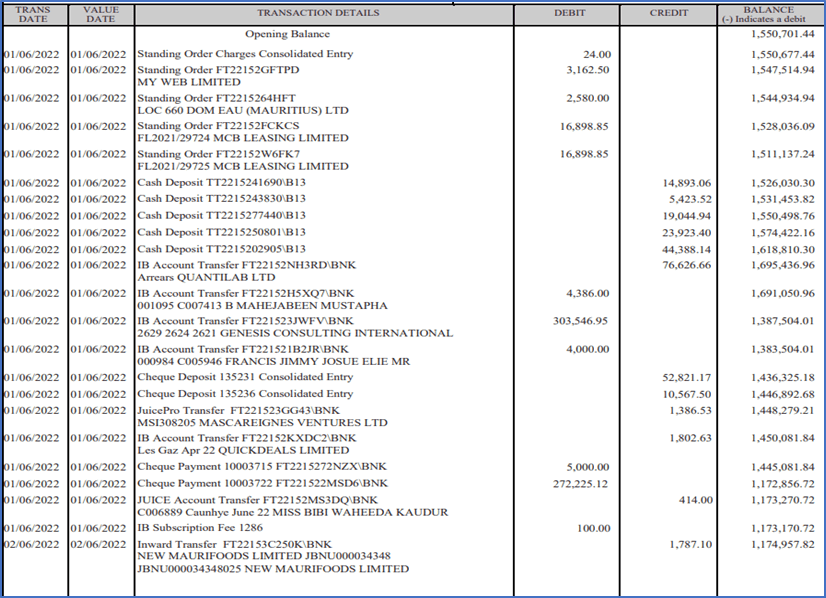 Load the image and convert it to grayscale. We then apply adaptive thresholding to obtain a binary image where the foreground (text) is white, and the background is black. We use morphological operations to remove the horizontal and vertical lines separately. For horizontal lines, we use a rectangular structuring element with a large width and a small height to cover the width of the image and dilate the foreground. Then we subtract the dilated image from the thresholded image to obtain an image with only horizontal lines. We do the same for vertical lines using a structuring element with a large height and a small width.
Load the image and convert it to grayscale. We then apply adaptive thresholding to obtain a binary image where the foreground (text) is white, and the background is black. We use morphological operations to remove the horizontal and vertical lines separately. For horizontal lines, we use a rectangular structuring element with a large width and a small height to cover the width of the image and dilate the foreground. Then we subtract the dilated image from the thresholded image to obtain an image with only horizontal lines. We do the same for vertical lines using a structuring element with a large height and a small width.- Finally, combine the images with both horizontal and vertical lines removed using a bitwise OR operation. The resulting image
removed_lines, will have both horizontal and vertical lines removed.
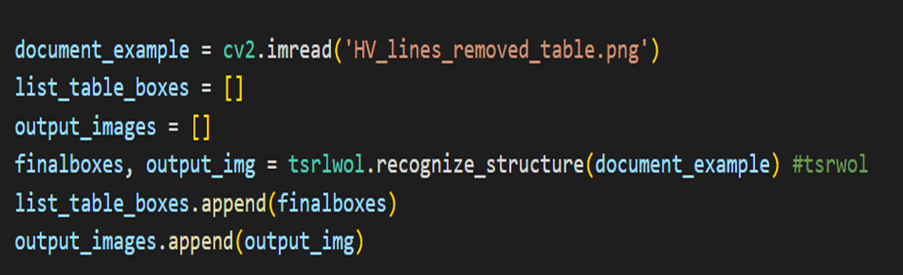
 Load the image with horizontal and vertical lines. We then initialize the Multi-Type TD-TRS detector and perform text detection on the image.
Load the image with horizontal and vertical lines. We then initialize the Multi-Type TD-TRS detector and perform text detection on the image.- Multi-Type TD-TRS (Text Detection and Text Recognition System) is a state-of-the-art deep learning model for detecting and recognizing text in images. One of the unique features of Multi-Type TD-TRS is its ability to handle multiple types of text, such as horizontal, vertical, and arbitrary oriented text. This is achieved by introducing different detection and recognition branches for each text type. The model is trained end-to-end using a combination of detection and recognition losses. Implementations of Multi-Type TD-TRS are available in several deep learning frameworks, including TensorFlow and PyTorch. The mttddet library provides an implementation of Multi-Type TD-TRS in PyTorch, which can be used for text detection and recognition in Python applications.

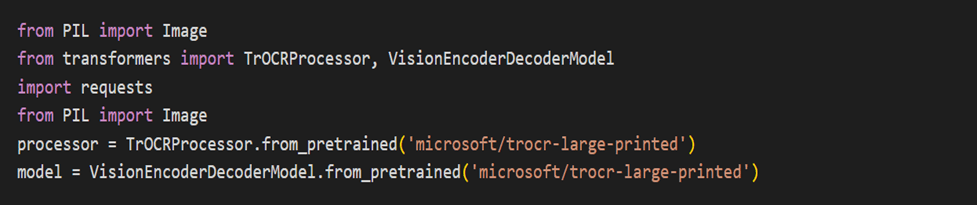
 Pass the image with bounding boxes drawn by Multi-Type TD-TRS to TROCR, you can first save the image with the bounding boxes.
Pass the image with bounding boxes drawn by Multi-Type TD-TRS to TROCR, you can first save the image with the bounding boxes.- TROCR is a Python package for Optical Character Recognition (OCR) that can be used to extract text from images. It supports various OCR engines such as Tesseract, Kraken, and OCRopus.
- Note that the bounding boxes are returned as a list of tuple, with each tuple containing the coordinates (x, y, width, height) of a bounding box. You can then use this text data and bounding boxes for further analysis or processing as needed.

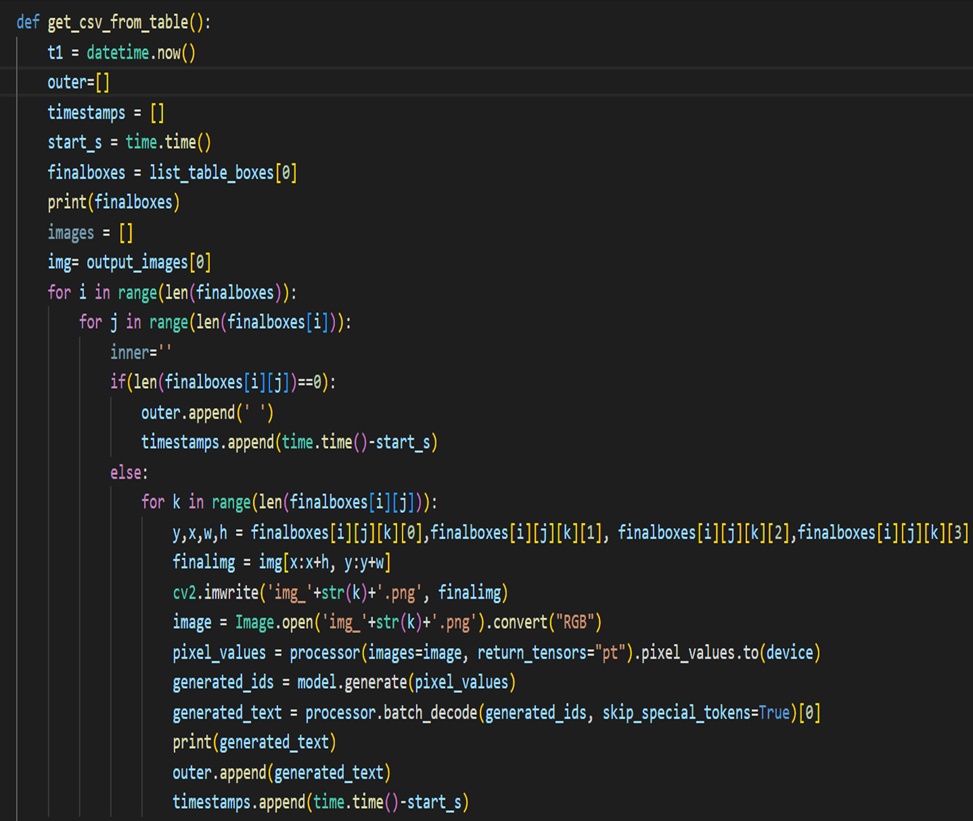

Unlock the potential of TROCR and enhance your financial data extraction capabilities today. Need to know more details on how we so it
Contact us here
Conclusion
Automating the process of extracting data from digital and scanned bank statements can greatly streamline financial data management and analysis. The TrOcr library in Python provides a powerful and versatile tool for this task, with its accuracy, versatility, customization option, and ease of use. By following the step-by-step guide outlined in this blog, you can effectively leverage TrOcr to extract data from digital and scanned bank statements in your Python applications.
Happy Reading!
Please see the part 1 : Extracting Data from Digital and Scanned Bank Statements using TrOcr & Detectron 2 – Part -1