


- May 5, 2023
- Posted by: Surya Ashokan
- Category: Data & Analytics
Introduction
Bank statements are essential financial documents that contain crucial information about a person or a business’s financial transactions. Extracting data from digital and scanned bank statements can be a time-consuming and error-prone process if done manually. However, with the help of Camelot library in Python for digital and Optical Character Recognition (OCR) technology for scanned, specifically TrOcr in Python, this process can be automated, saving time and reducing errors.
In this blog, we will explore how to use TrOcr, a popular Camelot library and OCR library in Python, to extract data from both digital and scanned bank statements. We will discuss the benefits of using TrOcr for bank statement data extraction and walk through step-by-step instructions on how to implement it in your Python code.
Why Use Camelot for Digital Bank Statement Data Extraction?
Camelot is a powerful Python library that is specifically designed for extracting tabular data from PDFs, making it ideal for digital bank statement data extraction. Here are some reasons why Camelot is a top choice for this task:
- Accuracy: Camelot uses advanced algorithms to accurately identify and extract tables from PDFs, even when dealing with complex layouts or multiple tables on a page.
- Flexibility: Camelot supports different types of PDF layouts, including single-page, multi-page, and scanned PDFs, making it suitable for extracting data from various types of digital bank statements.
- Customization: Camelot provides options for customizing table extraction settings, such as specifying table regions, column separators, and row separators, to suit your specific bank statement templates.
- Easy Integration: Camelot offers a simple and intuitive API for integrating table extraction capabilities into your Python code, making it accessible to users with different levels of programming experience.
Step-by-Step Guide to Digital Bank Statement Data Extraction with Camelot in Python
Now let’s dive into the step-by-step guide on how to use Camelot for digital bank statement data extraction in Python. Here’s an overview of the entire process:
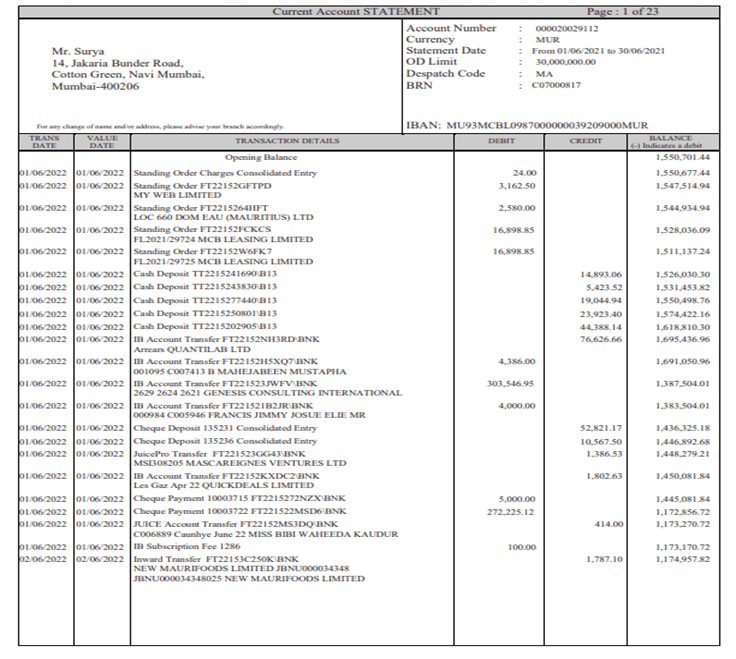
Sample digital bank document:
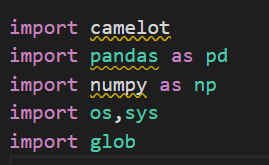
1. Installing and importing the Camelot Library: We will start by installing and importing the Camelot library in Python, along with any other required dependencies.

2. Loading the Digital Bank Statement PDF: We will then load the digital bank statement PDF using Camelot, and pre-process it if necessary.


3. Extracting Tables from the PDF: Next, we will use Camelot to extract tables from the loaded PDF and store the extracted tables in a suitable format for further processing.
![]()
4. Data Cleaning and Extraction: We will then clean and pre-process the extracted tables to remove any unwanted characters or noise, and extract the relevant data such as transaction dates, amounts, and descriptions.

Output Results forDigital Bank Statement Data Extraction with Camelot in Python
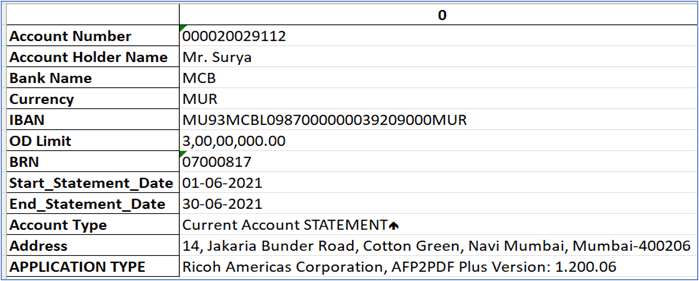
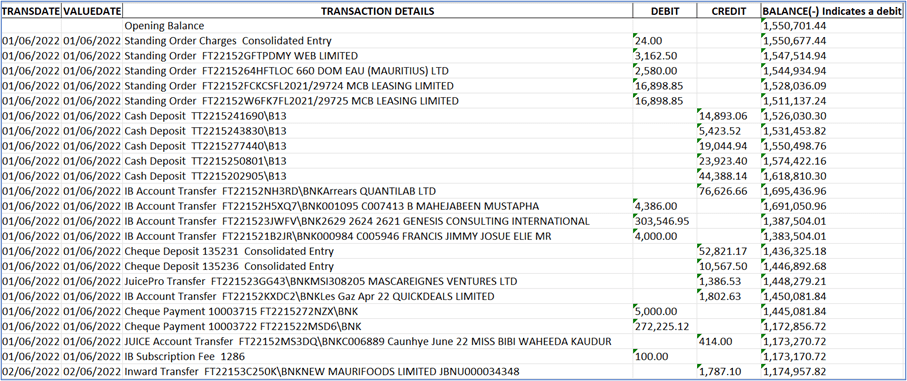

Automating the process of extracting data from digital bank statements can greatly improve the accuracy of financial data management. The Camelot library in Python provides a powerful and flexible tool for this task, with its accuracy, flexibility, customization options, and easy integration. By following the step-by-step guide outlined in this blog, you can effectively leverage Camelot to extract data from digital bank statements in your Python applications. Unlock the potential of Camelot and enhance your digital bank statement data extraction capabilities today!
Overall, these titles convey the value of using Camelot for digital bank statement data extraction, highlighting the benefits of improving financial data management and analysis.
Why Use TrOcr for Scanned Bank Statement Data Extraction?
TrOcr is a powerful OCR library in Python that is specifically designed for extracting text from images, making it ideal for scanned bank statement data extraction. Here are some reasons why TrOcr is a top choice for this task:
- Accuracy: TrOcr uses advanced image processing techniques to accurately recognize text from images, even in challenging conditions like low resolution, poor image quality, and different fonts.
- Versatility: TrOcr supports a wide range of image formats, including JPEG, PNG, TIFF, and PDF, making it suitable for extracting data from both digital and scanned bank statements.
- Customization: TrOcr allows you to train your own OCR models using your specific bank statement templates, which can lead to even higher accuracy and better results.
- Ease of Use: TrOcr provides a simple and user-friendly API for integrating OCR capabilities into your Python code, making it accessible even to those with limited programming experience.
Please see the part 2 : Extracting Data from Digital and Scanned Bank Statements using TrOcr & Detectron 2 – Part-2