



- May 31, 2022
- Posted by: Hrushikesh Raghavendra
- Category: Data engineering


Primary questions to answer in this article are:
1. What is Databricks?
2. Why Databricks?
3. Initial Setup of Databricks?
What is Databricks?
DataBricks is an organization and big data processing platform founded by the creators of Apache Spark.
DataBricks was founded to provide an alternative to the MapReduce system and provides a just-in-time cloud-based platform for big data processing clients.
DataBricks was created for data scientists, engineers and analysts to help users integrate the fields of data science, engineering and the business behind them across the machine learning lifecycle. This integration helps to ease the processes from data preparation to experimentation and machine learning application deployment.
According to the company, the DataBricks platform is a hundred times faster than the open source Apache Spark. By unifying the pipeline involved with developing machine learning tools, DataBricks is said to accelerate development and innovation and increase security. Data processing clusters can be configured and deployed with just a few clicks. The platform includes varied built-in data visualization features to graph data.
Databricks is integrated with Microsoft Azure, Amazon Web Services, and Google Cloud Platform, making it easy for businesses to manage a colossal amount of data and carry out Machine Learning tasks.
DataBricks is headquartered in San Francisco, California and was founded by Ali Ghodsi, Andy Konwinshi, Scott Shenker, Ion Stoica, Patrick Wendell, Reynold Xin and Matei Zaharia.
Why Databricks?
After getting to know What is Databricks Consulting Services, let us also get started with some of its key features. Below are a few benefits of Databricks:
- Language: It provides a notebook interface that supports multiple coding languages in the same environment. Using magical commands (%python, %r, %scala, and %sql), a developer can build algorithms using Python, R, Scala, or SQL. For instance, data transformation tasks can be performed using Spark SQL, model predictions made by Scala, model performance can be evaluated using Python, and data visualized using R.
- Productivity: It increases productivity by allowing users to deploy notebooks into production instantly. Databricks provides a collaborative environment with a common workspace for data scientists, engineers, and business analysts. Collaboration not only brings innovative ideas but also allows others to introduce frequent changes while expediting development processes simultaneously. Databricks manages the recent changes with a built-in version control tool that reduces the effort of finding recent changes.
- Flexibility: It is built on top of Apache Spark that is specifically optimized for Cloud environments. Databricks provides scalable Spark jobs in the data science domain. It is flexible for small-scale jobs like development or testing as well as running large-scale jobs like Big Data processing. If a cluster is idle for a specified amount of time (not-in-use), it shuts down the cluster to remain highly available.
- Data Source: It connects with many data sources to perform limitless Big Data Analytics. Databricks not only connects with Cloud storage services provided by AWS, Azure, or Google Cloud but also connects to on-premise SQL servers, CSV, and JSON. The platform also extends connectivity to MongoDB, Avro files, and many other files.
Initial Setup of Databricks
Learn how Indium is an industry leader in databricks implementation services in this success story: EDW And Data Lake For a Reinvestment Fund Solution Provider
Step 1. Search for Databricks in Google Market place and subscribe for 14 day free trial.
Step 2. After starting the trial subscription, you will receive a link from the Databricks menu item in Google Cloud Platform. This is to manage setup on the Databricks hosted account management page.
Step 3. After this step, you must create a Workspace which is the environment in Databricks to access your assets. For this, you need an external Databricks Web Application
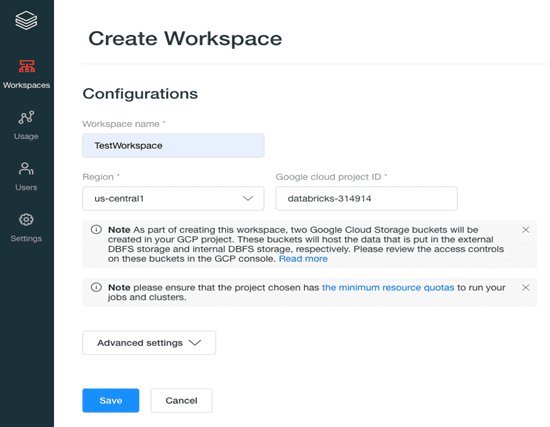 Step 4: To create a workspace, you need three nodes Kubernetes clusters in your Google Cloud Platform project using GKE to host the Databricks Runtime, which is your Data plane.
Step 4: To create a workspace, you need three nodes Kubernetes clusters in your Google Cloud Platform project using GKE to host the Databricks Runtime, which is your Data plane.
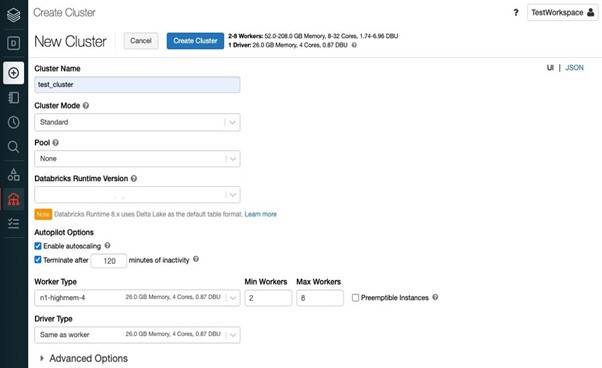
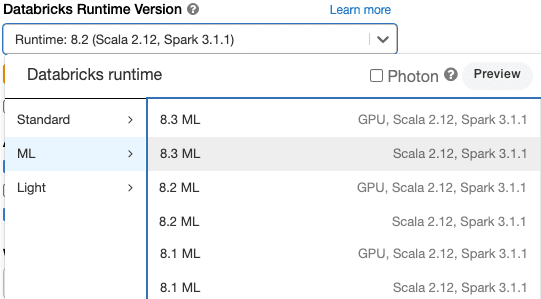
Step 5: We need to create a cluster to start working with Spark/Scala, a cluster is a combination of computation resources and configurations on which you can run jobs and notebooks. Some of the workloads that you can run on a Databricks Cluster include Streaming Analytics, ETL Pipelines, Machine Learning, and Ad-hoc analytics.
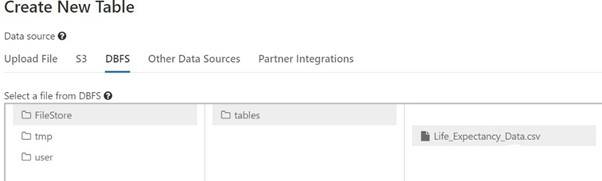
Step 6: We need to analyze the data on which we are going to develop a machine learning model. Upload the data, this creates a new table in the workspace.
The table can be created in two ways one through code and two through the UI, in this case we are using UI where we get options to change datatypes, Inferschema, first row as header, delmiter, etc.
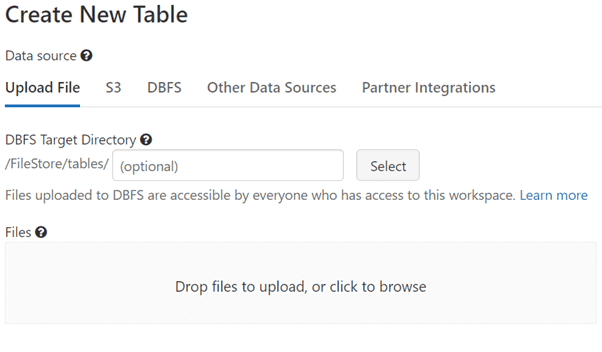
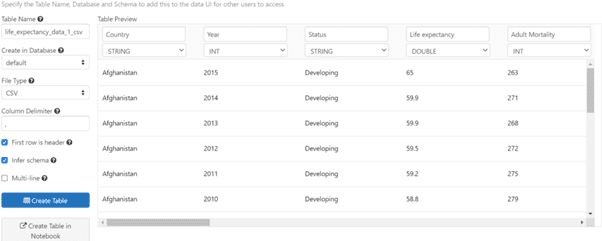
File Location is under DBFS filepath : /FileStore/tables/<file_name>. This filepath will be used to read the data.
Conclusion
This blog gives a brief introduction about databricks implementation Services and features but there are more features which are not covered in this, which would be covered in Part II of this blog.
After understanding completely What is Databricks, what are you waiting for! Get started! Companies need to understand what the insights of the data are, and how the data is stored and managed in Databricks.
In upcoming articles we would be covering reading data using pySpark, analyzing the data, EDA and model building using pyspark.
Please see the part 2 : The End-To-End ML Pipeline using Pyspark and Databricks (Part II)