



- May 17, 2023
- Posted by: Ashrulochan Sahoo
- Category: Data & Analytics

Introduction
More than ever, the human race is discovering, revolving, and revolving. The revolution in Artificial Intelligence Domain has brought the whole human species to a new Dawn of personalized services. With more people adapting to the Internet, demands of various services in different phases of life are increasing. Let’s consider the case of Covid Pandemic, the demons are still at war with. In the times of lockdown, to stay motivated we have used Audio Book applications, video broadcasting applications, attended online exercise, Yoga, even Consulted with Doctors through an Application. While the physical streets were closed, there was more traffic online.
All these applications, websites, which we have used, have a simple goal and that is a better service to the user. To do so, they collect personal information directly or indirectly, intentionally or for the sake of betterment. The machines, despite their size starting from laptops to smart watches, even voice assistants are listening to us, watching us every move we made, every word we uttered. Albeit their purpose of doing so is noble, but there’s no guarantee of leakage-proof, intruder-proof and spammers-proof data handling. According to a study by Forbes, on average there are 2.5 quintillion bytes of data generated per day, and this data is increasing year by year exponentially. Data Mining, Data Ingestion and Migration phases are the most vulnerable phases for potential data leakage. The surprising news is the cyber-attacks also happen at a rate of 18 attacks per minute. More than 16 lakh cybercrimes happened in last 3 years in India only.

Need of Data Masking
Besides the online scams and frauds Cyber Attacks, data breaches are major risks to every organization that mines personal data. A data breach is where the attacker gains access to millions to billions of people’s personal information like bank details, mobile numbers, social service numbers, etc. According to the Identity Theft Resource Center (ITRC), 83% of the 1,862 data breaches in 2021 involved sensitive data. These incidents are now considered as equipment of modern warfare.
Data Security Standards
Based on the countries and regulatory authorities there are different rules that need to be imposed to protect sensitive information. European Union States promotes General Data Protection Regulation (GDPR) to protect personal and racial information along with digital information, Health records, biometric and genetic data of individuals. United States Department of Health and Human Service (HHS) passed Health Insurance Portability and Accountability Act that protects and promotes security standards for Privacy of Individually Identifiable Health Information. International Organization for Standardization and the International Electrotechnical Commission’s (IOS/IEC) 27001 and 27018 security standards promote confidentiality, integrity and availability norms for Big Data organizations. In Extract Transform and Load (ETL) services, Data Pipeline services or Data Analytics services sticking to these security norms are crucial and liberating.
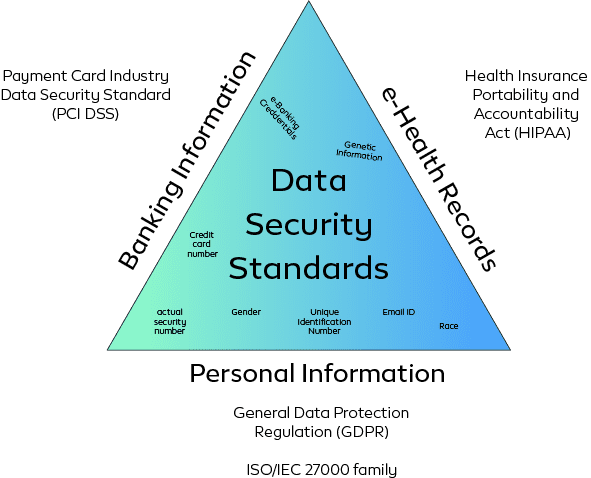
Different Security Standards
Read this insightful blog post on– Maximizing AI and ML Performance: A Guide to Effective Data Collection, Storage, and Analysis
Techniques to Protect Sensitive Data
All the security protocols and standards can be summarized into three different techniques: Data De-Identification, Data Encoding and Data Masking. Data De-identification is used to protect sensitive data by removing or obscuring identifiable information. In De-identification technique the original sensitive information will be anonymized i.e., to completely remove those records from database, pseudonymization i.e., to replace the sensitive information with aliases, and lastly the aggregation where data will be grouped and summarized and then will be presented or shared rather than sharing the original elements.
In de-identification the original data format or structure may not be retained. Data Encoding refers to the technique of encoding the data in cyphers which can later be decoded by authorized users. Various encoding techniques are Encryption – key based encryption of data, Hashing – Original data will be converted to hash values using Message Digest (md5), Secure Hash Algorithm (sha1) or BLAKE hashing, etc. In other hand Data masking is the technique of replacing the original data with factious or obfuscated data where the masked data retains the format and structure of original data. All these techniques do not fall into a particular class or follow a hierarchal trend. They are used alone with one another based on the use cases and the cruciality of the data.
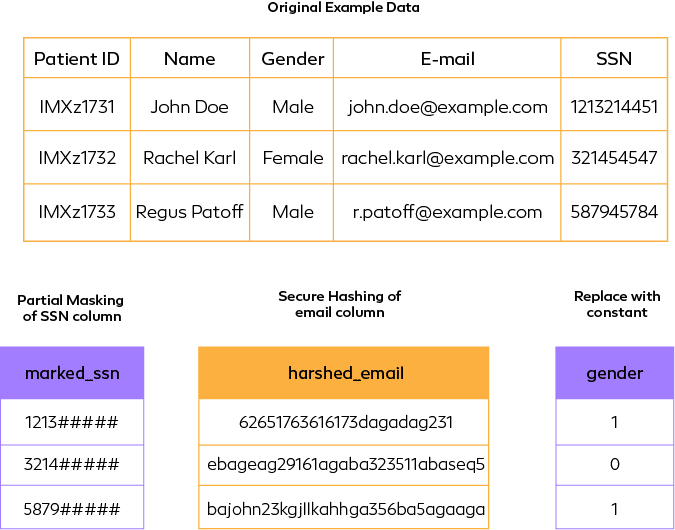
Comparative abstraction of major techniques
Data Masking is of two types i.e., Static Data Masking (SDM) and Dynamic Data Masking (DDM). Static Data masking involves replacing sensitive data with realistic but fictitious data with the structure and format of original data. Static Data Masking involves substitution – replacing the sensitive data with fake data, Shuffling – Shuffle the data in a column to manipulate original value and its references, Nulling – Sensitive data will be replaced with Null values. Encryption – encryption of sensitive information, Redaction – partially masking the sensitive data where only one part of the data is visible. Whereas Dynamic Data Masking involves Full masking, partial masking – Mask portion, random masking – mask at random, conditional masking – mask when a specific condition is met, Encoding and Tokenization- convert data to non-sensitive token value that preserves the format and length of original data.
SDM masks data at rest by creating a copy of an existing data set. The copied and masked data can only be used to share in analysis and production teams. Updates to the original data do not reflect in masked data until a new copy is made whereas DDM masks data at query time. The updated data also comes in masked format because of the query. The liveness of data remains intact without worrying about data silos. SDM is the primary choice of data practitioners as it is reliable and completely isolated original data. In other hand, DDM depends on query time masking which poses a chance of failure at some adverse instances.
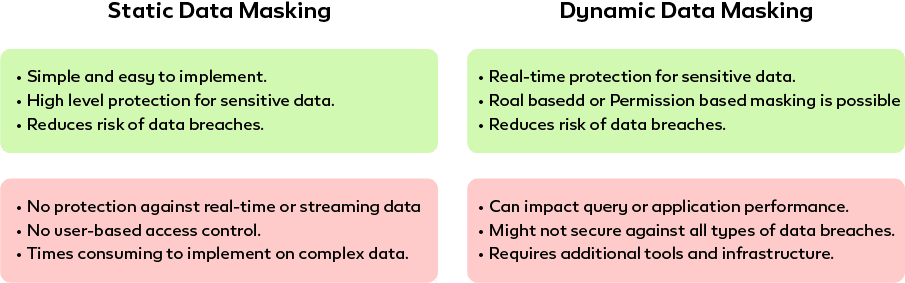
SDM vs DDM
Data Masking Best Practices
Masking of sensitive data depends on the use case of the resultant masked data. It is always recommended to mask the data in the non-production environment. However, there are some practices that need to be considered for secure and fault-tolerant data masking.
1. Governance: The organization must follow common security practices based on the country it’s operating in and the international data security standards as well.
2. Referential Integrity: Tables with masked data should follow references accordingly for the purpose of join while analyzing the data without revealing sensitive information.
3. Performance and Cost: Tokenization and Hashing often convert the data to a standard size which may be more than actual size. Masked data shouldn’t impact the general query processing time.
4. Scalability: In case of big data the masking technique should be able to mask large dataset and stream data as well.
5. Fault-tolerance: The technique should be tolerant to minimal data ugliness like extra space, comma, special characters etc. By scrutinizing the masking process and resultant data often helps to avoid common pitfalls.
Protect your sensitive data with proper data masking techniques. Contact us today to get in Touch.
Click here
Conclusion
In conclusion, the advancements in technology, particularly in the domain of Artificial Intelligence, have brought about a significant change in the way humans interact with services and each other. The COVID-19 pandemic has further accelerated the adoption of digital technologies as people were forced to stay indoors and seek personalized services online. The increased demand for online services during the pandemic has shown that technology can be leveraged to improve our lives and bring us closer to one another even in times of crisis. As we continue to navigate the post-pandemic world, the revolution in technology will play a significant role in shaping our future and enabling us to live a better life.