



- October 30, 2023
- Posted by: Prashanth Srinivasan Sarkar
- Category: Data & Analytics

Part One Recap
In the first part of our exploration, we laid the foundation for evaluating NLP models in the financial landscape. We emphasized the critical role of high-quality datasets and dived into the capabilities of foundational NLP models, particularly distilbert-base-uncased-finetuned-sst-2-english. Understanding the importance of data selection and model choice forms the bedrock for our deeper dive into specialized models tailored for financial analysis.
Comparative Evaluation
We can compare the results of all 3 models against each other to determine which one performs better. The metrics used are Accuracy, precision, recall and F1 score. Accuracy, recall, precision, and F1 score are common performance metrics used to evaluate the performance of classification models, such as in natural language processing tasks like sentiment analysis or text categorization. Each metric provides insights into different aspects of the model’s predictions.
Accuracy is the most basic evaluation metric and represents the overall correctness of the model’s predictions. It is calculated as the ratio of correctly predicted instances (true positives and true negatives) to the total number of instances in the dataset. While accuracy is a useful metric, it can be misleading when dealing with imbalanced datasets where one class dominates the others, leading to high accuracy even if the model performs poorly on the minority class.
Recall, also known as sensitivity or true positive rate, measures the ability of the model to correctly identify all positive instances (true positives) out of all the actual positive instances (true positives + false negatives). It gives insights into the model’s ability to avoid false negatives and capture relevant positive instances. A high recall indicates that the model is effective at identifying positive cases, even if it means having more false positives.
Precision measures the accuracy of the model’s positive predictions by calculating the ratio of true positives to the sum of true positives and false positives. It shows how well the model avoids false positives. A high precision indicates that the model is conservative in its positive predictions and minimizes false alarms.
The F1 score is the harmonic mean of precision and recall and is used to balance both metrics. It provides a single metric that combines precision and recall, allowing a more comprehensive evaluation of the model’s performance. The F1 score is particularly useful in cases where both high precision and high recall are desired, as it penalizes models that prioritize one metric over the other. A higher F1 score indicates a better balance between precision and recall.
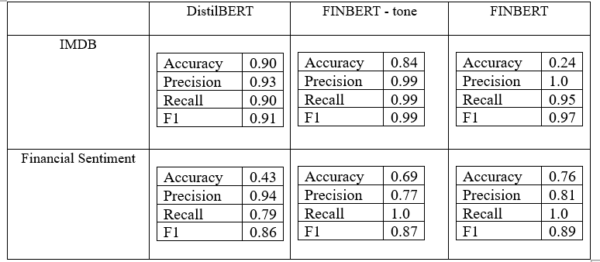
Evaluating each model, it is clear that all 3 have a very good true positive rate, resulting in high precision, recall and F1 score across the board. However, DistilBERT has a very low accuracy on the financial dataset while FINBERT has a very low accuracy in the IMDB dataset. This effectively demonstrates the generalization capability of the BERT model when it is not finetuned for any specific domain. It also demonstrates the capability of FINBERT to perform well with financial data as well as its inability to generalize to non-financial data.
FINBERT-tone however, is an entirely different case. It appears to have an increased generalizing capability than its non-fine-tuned variant as demonstrated by its performance on the IMDB dataset. However, it is not as capable as FINBERT when classifying, this is in direct contradiction of the claims of the developers on the hugging face platform who claimed that this model would be more capable than FINBERT for sentiment analysis tasks. This may be attributed to many areas within the methodology. However, it is likely that FinBERT-tone is much more sensitive to tone, and this may have resulted in its inability to perform a simple binary classification. As the ability to gauge nuance increases, the model has deviated from seeing in black and white.
It is important to note, however, that in the evaluation process, we have ignored the neutral labels in the financial sentiment dataset and have ignored the neutral classifications of the models that have a neutral class. Thus, the data may be significantly skewed based on the model’s capability to handle neutral sentiment.
Explore More NLP Insights
Summarization
bart-large-cnn
Link: https://huggingface.co/facebook/bart-large-cnn
BART (Bidirectional and Auto-Regressive Transformers) is a state-of-the-art language generation model introduced by Facebook AI Research (FAIR). Unlike traditional transformer models that are primarily designed for tasks like language understanding, BART excels in both text generation and comprehension. The model employs a two-step process, consisting of bidirectional pre-training and auto-regressive decoding. During pre-training, BART learns to predict masked words in a bidirectional manner, similar to BERT. However, it also utilizes an auto-regressive decoder to predict subsequent words, enabling it to generate coherent and contextually relevant text.
One of BART’s key strengths lies in its ability to perform various text generation tasks, such as text summarization, machine translation, and question answering, by fine-tuning the pre-trained model on specific datasets. Its auto-regressive nature allows it to generate lengthy and coherent responses, making it particularly effective for tasks requiring context-aware language generation. BART has demonstrated exceptional performance in various natural language processing tasks and has quickly become a popular choice among researchers and developers for its versatility and ability to handle both text comprehension and generation with impressive results.
The BART-large model has 400 million parameters. It contains 12 layers on the encoder and decoder side with 16 attention heads. It has a vocab size of 50264 and takes a maximum input length of 1024.
Choosing BART can be a highly advantageous decision due to its remarkable versatility and prowess in both text comprehension and generation tasks. As a bidirectional and auto-regressive transformer model, BART combines the strengths of pre-training with bidirectional context understanding, similar to BERT, and auto-regressive decoding to generate coherent and contextually relevant text. This unique architecture enables BART to excel in a wide range of natural language processing tasks, such as text summarization, machine translation, and question answering.
More information: https://github.csom/facebookresearch/fairseq/tree/main/examples/bart
Code snippet:
import pandas as pd
import torch
import transformers
from transformers import pipeline
df = pd.read_csv(dataset path)
df.head()
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained(“facebook/bart-large-cnn”, max_length = 1024)
model = AutoModelForSeq2SeqLM.from_pretrained(“facebook/bart-large-cnn”)
nlp = pipeline(“summarization”, model=model, tokenizer=tokenizer, device = 0)
X = df.iloc[:,full text column]
y = df.iloc[:,summary column]
!pip install torchmetrics
from torchmetrics.text.rouge import ROUGEScore
from transformers import pipeline
torch.cuda.set_device(0)
device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
rouge = ROUGEScore()
rougeL = 0
rouge1 = 0
rouge2 = 0
count = 0
wrong_dict = {}
for input_sequence in X:
try:
tokenized = tokenizer(input_sequence, max_length = 1024, return_tensors = ‘pt’).to(device)
summary_ids = model.generate(tokenized[“input_ids”], num_beams=2)
summary = tokenizer.batch_decode(summary_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
# results = nlp(input_sequence)
# summary = results[0][‘summary_text’]
rougeL += rouge(summary, y[count])[‘rougeL_fmeasure’].item()
rouge1 += rouge(summary, y[count])[‘rouge1_fmeasure’].item()
rouge2 += rouge(summary, y[count])[‘rouge2_fmeasure’].item()
except:
pass
count += 1
print(count,’/2000 complete’, end = ‘\r’)
# if count == 2000:
# break
rouge1_score = rouge1/count
rouge2_score = rouge2/count
rougeL_score = rougeL/count
print(‘\nRougeL fmeasure:’, rougeL_score)
print(‘Rouge1 fmeasure:’, rouge1_score)
print(‘Rouge2 fmeasure:’, rouge2_score)
Financial Summarization-PEGASUS
Link: https://huggingface.co/human-centered-summarization/financial-summarization-pegasus
PEGASUS is an advanced language model developed by Google Research, known for its exceptional capabilities in abstractive text summarization. Unlike extractive summarization, where sentences are selected from the original text, PEGASUS generates concise and coherent summaries by paraphrasing and reorganizing the content. The model’s architecture is built upon the Transformer-based encoder-decoder framework, and it is trained on a large corpus of diverse data to develop a deep understanding of language semantics and coherence.
One of PEGASUS’s key strengths lies in its ability to produce informative and contextually accurate summaries across various domains and languages. By leveraging pre-training and fine-tuning techniques, PEGASUS can be tailored to specific summarization tasks, achieving remarkable performance in summarizing long documents, news articles, and other text types. Its remarkable generalization abilities make it a valuable tool for generating high-quality summaries in scenarios where human-like summarization is essential, such as content curation, document analysis, and information retrieval.
This fine-tuned model of PEGASUS claims to have an improved performance for financial summarization. It contains 16 layers in the encoder and decoder and takes a maximum input length of 512 tokens. The vocab size is 96103, however, the summary length is much shorter than BART.
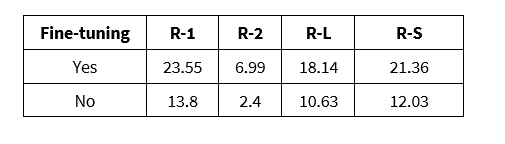
Selecting PEGASUS can be a highly advantageous decision for tasks requiring abstractive text summarization. Its exceptional capabilities in generating coherent and informative summaries make it an invaluable asset in various domains. Unlike extractive summarization approaches, PEGASUS excels in paraphrasing and reorganizing content, enabling it to produce concise and contextually accurate summaries that capture the essence of the original text.
PEGASUS’s Transformer-based encoder-decoder architecture, combined with extensive pre-training on diverse datasets, equips it with a deep understanding of language semantics and coherence. This extensive training empowers PEGASUS to generalize effectively across different domains and languages, ensuring its performance remains robust and reliable. From summarizing long documents to news articles and more, PEGASUS can be fine-tuned to tailor its summarization abilities to specific tasks, making it an ideal choice for applications that demand human-like summarization quality, such as content curation, document analysis, and knowledge extraction. In summary, PEGASUS’s proficiency in abstractive summarization and its adaptability across diverse domains make it a compelling and powerful choice for tasks that require top-notch language understanding and summarization capabilities.
Code snippet:
!pip install sentencepiece
import sentencepiece as sentencepiece
from transformers import PegasusTokenizer, PegasusForConditionalGeneration
model_name = “human-centered-summarization/financial-summarization-pegasus”
tokenizer = PegasusTokenizer.from_pretrained(model_name)
model = PegasusForConditionalGeneration.from_pretrained(model_name)
import pandas as pd
#bitcoin articles dataset
df = pd.read_csv(dataset path)
df.head()
from transformers import pipeline
nlp = pipeline(“summarization”, model=model, tokenizer=tokenizer, device = 0, max_length=80, min_length=50)
!pip install torchmetrics
from torchmetrics.text.rouge import ROUGEScore
import torch
torch.cuda.set_device(0)
device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’)
rouge = ROUGEScore()
from pprint import pprint
print(nlp([X[0]])[0][‘summary_text’])
#code for getting metrics on dataset
rougeL = 0
rouge1 = 0
rouge2 = 0
count = 0
wrong_dict = {}
for input_sequence in X:
try:
summary = nlp(input_sequence)[0][‘summary_text’]
rougeL += rouge(summary, y[count])[‘rougeL_fmeasure’].item()
rouge1 += rouge(summary, y[count])[‘rouge1_fmeasure’].item()
rouge2 += rouge(summary, y[count])[‘rouge2_fmeasure’].item()
except:
pass
count += 1
print(count,’/2000 complete’, end = ‘\r’)
# if count == 5:
# break
rouge1_score = rouge1/count
rouge2_score = rouge2/count
rougeL_score = rougeL/count
print(‘\nRougeL fmeasure:’, rougeL_score)
print(‘Rouge1 fmeasure:’, rouge1_score)
print(‘Rouge2 fmeasure:’, rouge2_score)
Comparative Evaluation
We can compare the results of both models against each other to determine which one performs better. The metric used for this was ROUGE score fmeasure. ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is a set of metrics commonly used to evaluate the quality of automatic text summarization. Its primary focus is on measuring the similarity between the generated summary and one or more reference summaries created by humans. ROUGE calculates various metrics, including ROUGE-N, ROUGE-L, and ROUGE-W, each evaluating different aspects of summarization quality.
ROUGE-N measures the n-gram overlap between the generated summary and the reference summary, where “N” represents the number of consecutive words in the n-gram. ROUGE-L, on the other hand, evaluates the longest common subsequence between the generated and reference summaries, considering not only individual words but also the order in which they appear. Lastly, ROUGE-W extends the evaluation to weighted word sequences, accounting for the importance of words in the summaries based on their frequency in the reference summaries.
ROUGE scores are widely used in research and development of automatic summarization systems, as they provide objective and quantitative measures to assess the quality of generated summaries. Higher ROUGE scores indicate better similarity between the generated summary and the human-created references, suggesting that the summarization system produces summaries that capture the essential content and structure of the original text more effectively. However, ROUGE scores should be interpreted alongside other metrics and human evaluation to ensure a comprehensive assessment of the summarization system’s performance.
ROUGE F-measure, often referred to as ROUGE-F1, is a commonly used evaluation metric in automatic text summarization tasks. It is a combination of precision and recall and is calculated as the harmonic mean of these two metrics.
Precision measures the proportion of words in the generated summary that also appear in the reference summary. It represents the ability of the summarization system to avoid producing irrelevant words that do not appear in the human-created reference summary. Recall, on the other hand, measures the proportion of words in the reference summary that are also present in the generated summary. It represents the ability of the summarization system to capture important information from the original text. By taking the harmonic mean of precision and recall, the ROUGE F-measure balances both metrics and provides a single score that evaluates the overall performance of the summarization system. A higher ROUGE F-measure indicates a better balance between precision and recall, suggesting that the summarization system produces summaries that are both concise and comprehensive, capturing the relevant content from the original text effectively.
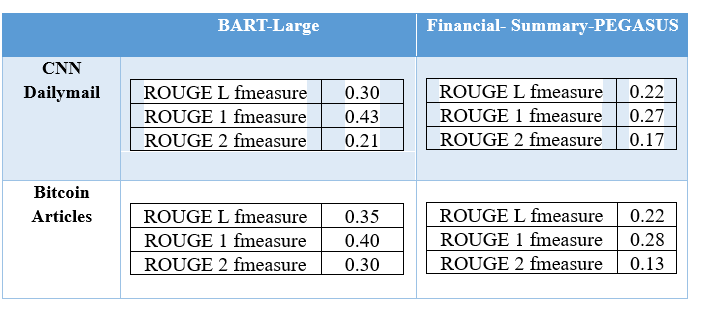
From the result analysis, it is evident that the BART model outperforms the PEGASUS model. We can attribute this to many factors including the fact that BART can handle a longer token length, making it easier for the model to handle longer dependencies. It may also be due to the training methods each model has been developed with. Or, we can attribute this large variation to BART’s architecture and the advantage of using an autoregressive decoder. Nonetheless, it is clear that BART is the preferred model regardless of what data it is summarizing.
Discover Advanced NLP Solutions
Conclusion
Upon conducting a thorough evaluation of all the models on two distinct datasets, the findings provide robust and well-justified conclusions that bear significant implications for text classification and summarization tasks.
For text classification, the results unambiguously point to FINBERT as the top-performing model. Its exceptional performance in handling financial text data showcases its specialization and domain-specific expertise, making it the ideal choice for financial sentiment analysis. While FINBERT-tone claimed to outperform the base model, this could not be substantiated by the evaluation, raising questions about its purported advantages in text classification tasks. Furthermore, the evaluation demonstrates that DistilBERT and, by extension the BERT base model, exhibit remarkable performance on more general datasets, illustrating their versatility and adaptability to various text classification challenges, including financial data analysis.
Moving to the task of summarization, the evaluation decisively positions BART as the clear winner. Its superior performance across both general and domain-specific datasets sets it apart from other models, including PEGASUS. BART’s abstractive summarization capabilities allow it to generate coherent and informative summaries that capture the essence of the original text, making it the preferred choice for summarization both general and domain specific. Despite its competence, the evaluation indicates that PEGASUS could not contend with BART’s performance in summarization tasks.
In conclusion, the evidence-based conclusions drawn from the rigorous evaluation provide valuable insights for selecting the most suitable models for text classification and summarization tasks. FINBERT shines as the optimal choice for text classification, particularly in financial domains, while BART emerges as the superior model for summarization, showcasing its capabilities in producing accurate and contextually rich summaries. These findings contribute to advancing the understanding of NLP model performance, guiding practitioners, and researchers in making informed decisions, and elevating the effectiveness of NLP applications in diverse real-world scenarios.