


- April 2, 2019
- Posted by: Satish Pala
- Category: Big Data
Firstly, it’s important to understand a few basic elements before we focus on what Kubernetes is and how it matters in the Big Data world.
What is a Virtual Machine (VM)?
With the evolution of virtualization, the most important component that has gained popularity is a guest environment on a host OS environment.
A virtual machine (VM) is an emulation of a computer system which means it acts like a physical computer and provides similar functionality albeit not physical. There are different kinds like
- System VM which is like a clone for a real machine providing functionality needed to execute entire operating systems and
- Process VM which is designed to provide a platform-independent programming environment. While there are advantages of a VM like running multiple OS on a single physical computer without any intervention, being widely available and easy to deploy, it has some challenges in resource efficiency and performance stability.
Cutting edge Big Data Engineering Services at your Finger Tips
Read More
What is a Container and how does it differ from a VM?
(Definition Source: https://aws.amazon.com/containers/)
The necessity for applications to run quickly and from various computing environments, the concept of containers evolved.
Containers provide a standard way to package your application’s code, configurations, and dependencies into a single object.
Containers share an operating system installed on the server and run as resource-isolated processes, ensuring quick, reliable, and consistent deployments, regardless of environment.
Containers’ speed, agility, and portability make them yet another tool to help streamline software development.

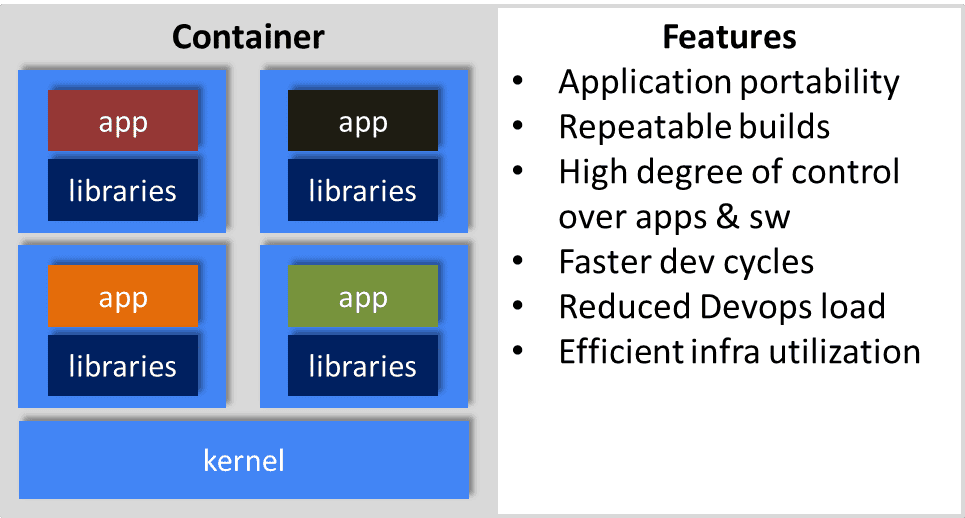
A number of container technologies are available. One of the more popular platforms is Docker, which is a management system that’s used to create, manage, and monitor Linux containers.
Ansible is another container-management system favored by Red Hat. Microsoft has Windows Container and Linux container service as a VM on Microsoft Hyper-V.
Docker and Ansible can manage Windows-based servers providing container support.
Containers and virtual machines are two ways to deploy multiple, isolated services on a single platform.
One of the key differences is the way virtualization is done – container provides a way on the OS itself so that multiple workloads run on the same OS instance while VM runs multiple OS as virtualization is done at the hardware layer.




What is Kubernetes? How is it different from Docker?
Kubernetes (k8s) is an open-source system for automating deployment, scaling, and management of containerized applications.
Kubernetes is the container orchestrator that was developed at Google and was later donated to the CNCF and has now become open source.
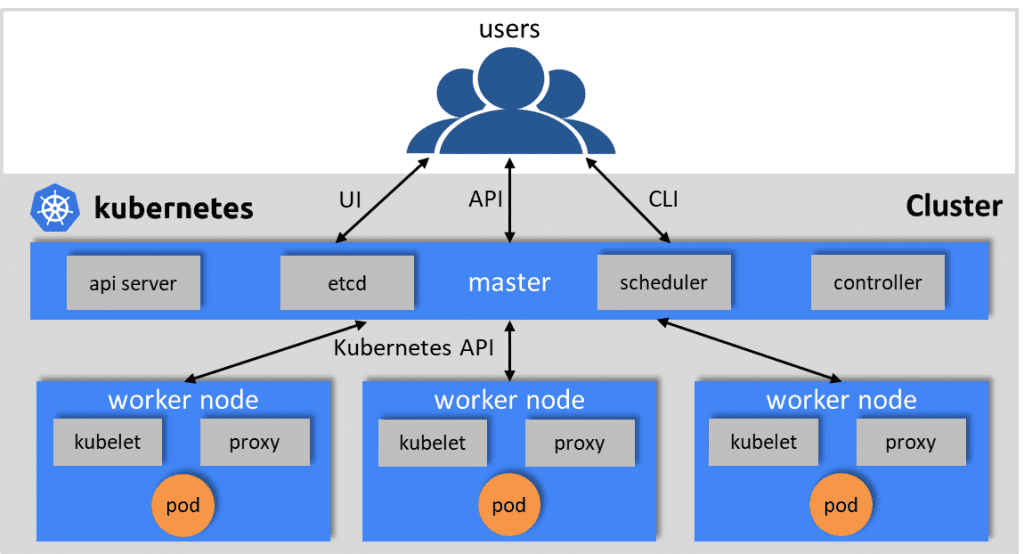
A Kubernetes cluster has a minimum of one master node for cluster management and one or more nodes as workers.
These worker nodes contain containerized apps running using pods. One or more containers are grouped logically as a pod within a worker node.
Within a pod, these containers can run on a host, share resources like networking, storage and runtime information. A kubelet is the primary node agent that runs on each node.

Kubernetes can’t be compared directly with Docker however it can be compared with Docker Swarm.
While Docker provides an open standard for packaging and distributing containerized applications, there is a need for a solution to orchestrate containers – like container coordination and scheduling, communication within the application and scaling.
This is where popular options like Kubernetes, Mesos and Docker Swarm come into the picture – these tools provide an abstraction to make a cluster of machines behave like one big machine, which is key in a large-scale environment.
Docker Swarm is a cluster solution from Docker itself which means it has easy and efficient integration with Docker components and uses native API.
Kubernetes is a container orchestration system for Docker containers that is more extensive than Docker Swarm and is meant to coordinate clusters of nodes at scale in production in an efficient manner.
Why Kubernetes for Big Data?
Kubernetes’ primary objective is to manage and deploy applications. These applications store data to a data platform which raises the question on data platform itself in terms of orchestrating application data processing life cycle.
There is a need for applications to be able to communicate state by persisting data in any desired form like file, stream, or table via a data platform that manages this data in much the way Kubernetes manages applications using containers.
Big Data platforms have matured over the past decade or so in terms of
- Increased productivity thanks to tools like Hadoop and Spark
- Ability to serve customers better by being able to process variety of data like social media, CRM, and other customer centric data
- Detect and react to fraud and risk due to big data analytics systems that rely on machine-learning that are excellent at detecting patterns and anomalies real-time
However, one of the major challenges that organizations face is to quickly scale up in terms of IT infrastructure necessary to support big data analytics initiatives.
Adequate Storage to house the data, network bandwidth to transfer it to and from analytics systems, and compute resources to perform those analytics are all expensive to purchase and maintain.
To alleviate this problem, some use cloud-based analytics, but that usually doesn’t eliminate the infrastructure problems entirely.
As a result, big data systems have always stressed storage systems. HDFS and other tools like MapR FS support performance and storage needs of a big data application.
However, there is a need for a better management of throughput, storage and performance.
This is where Kubernetes can help as it has the ability to simultaneously run multiple versions of big data tools like Spark that interface transparently to machine learning tools like TensorFlow, Keras, etc,.
You could have Big Data solutions without Hadoop layer on Kubernetes. There are more persistent storage options to run stateful applications on Kubernetes, depending on data type, such as object storage, file systems, software defined storage, etc,.
More and more Big Data Tools are running on Kubernetes such as: Apache Spark, Apache Kafka, Apache Flink, Apache Cassandra, Apache Zookeeper, etc.
Single container orchestrator for all applications – For example, Kubernetes can manage both data processing and applications within a single container orchestrator.
Increased server utilization – For example, share nodes between Kafka for streaming and run a web server without the need to statically partition nodes.
Better scheduling of workloads – For example, Kubernetes allows you to safely co-schedule batch and real-time workloads
Reduction in operational overhead – For example: When using Kafka on Kubernetes, you can reduce the overhead for a number of common operational tasks in Kafka like managing broker config, with standard cluster resource manager features.
Sample Big Data Architecture on Kubernetes – Apache Spark on k8s
(Source: https://spark.apache.org/docs/2.3.0/running-on-kubernetes.html)
Spark can run on clusters managed by Kubernetes. This feature makes use of native Kubernetes scheduler that has been added to Spark. The following diagram illustrates a spark integration with k8s cluster.

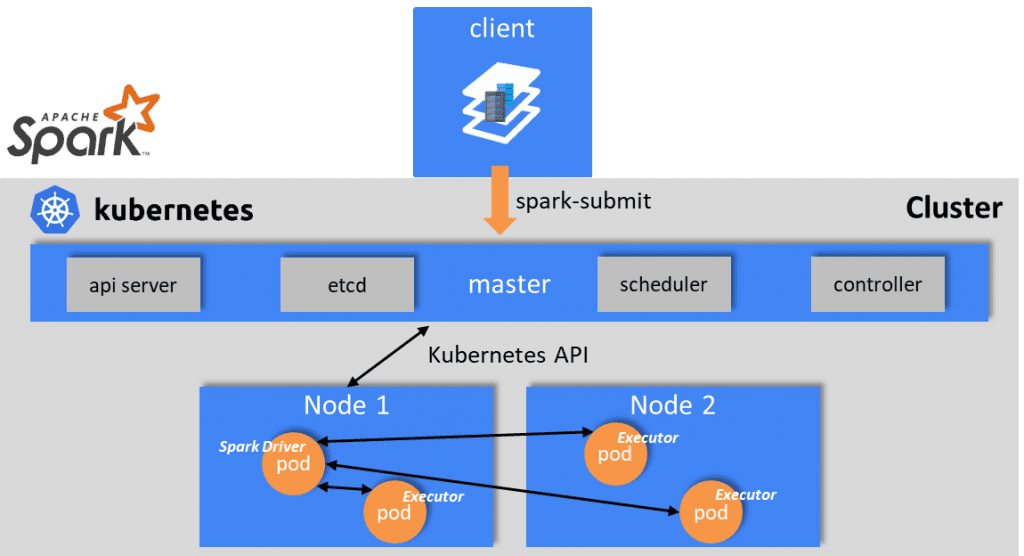
The submission mechanism works as follows:
- Spark creates a Spark driver running within a Kubernetes pod.
- The driver creates executors which are also running within Kubernetes pods and connects to them and executes application code.
- When the application completes, the executor pods terminate and are cleaned up, but the driver pod persists logs and remains in “completed” state in the Kubernetes API until its eventually garbage collected or manually cleaned up.
Note that in the completed state, the driver pod does not use any computational or memory resources. The driver and executor pod scheduling is handled by Kubernetes.
Leverge your Biggest Asset Data
Inquire Now
For additional information, refer to
Kubernetes: https://kubernetes.io/
Docker: https://www.docker.com/
Github docs: https://apache-spark-on-k8s.github.io/userdocs/running-on-kubernetes.html
Spark on Azure Kubernetes Service: https://docs.microsoft.com/en-us/azure/aks/spark-job