


- March 22, 2023
- Posted by: Atul Prasad
- Category: Data & Analytics

Corporates manage multiple data marts around the data warehouse and complex ETL pipelines to make it available to the BI tools for various Subject Areas or Lines of Business. It is always an additional management overhead and administration to satisfy each of the Business Areas.
The requests for data are now made in real-time rather than in batches to accommodate all business requirements. The scale adds to the system’s complexity and difficulty in addition to the things mentioned above. Therefore, it is essential to address optimization and cost reduction from the beginning to the end of a project.
Why BI Engine
BI Engine is helpful and acts as an acceleration layer between BigQuery and BI Tools. So overall the vision for BigQuery BI Engine is to democratise BI, enabling business analysts to perform interactive analytics in real-time. Now, three key value propositions of BigQuery BI Engine that is:
- It provides sub-second queries:
- Column-orientated. Dynamic in-memory execution engine.
- Horizontal scaling to support higher concurrency.
- Naive integration with BigQuery Streaming for real-time data refreshes.
- It simplifies the architecture:
- Built on existing BigQuery Storage.
- Eliminates the need to manage BI Servers, ETL pipelines, or complex extracts.
- No need to build and manage traditional OLAP cubes.
- Open API for partner integration
- It has smart tuning built:
- In-memory cache optimization avoids querying raw data.
- Ability to scale capacity up and down inside BigQuery UI.
- Full visibility into metrics including aggregate refresh time, cache hit ratios, query latency, etc. inside Stackdriver.
Architecture of BI Engine
Before jumping to the BI Engine we need to understand BigQuery Architecture.
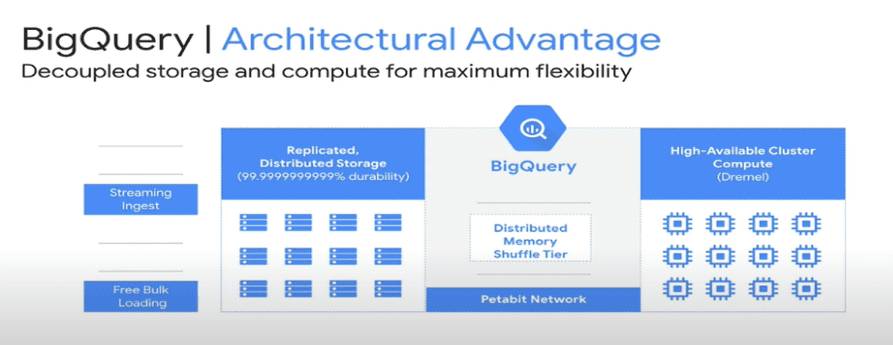 Let’s start with the high-level architecture of BigQuery, we see three main pieces here, one on the left is storage, that’s where all of its data is stored. On the right, compute that’s where query processing happened. And between them a shuffle layer, which facilitates distributed processing.
Let’s start with the high-level architecture of BigQuery, we see three main pieces here, one on the left is storage, that’s where all of its data is stored. On the right, compute that’s where query processing happened. And between them a shuffle layer, which facilitates distributed processing.
Now let’s see where the BI Engine fits into this picture.
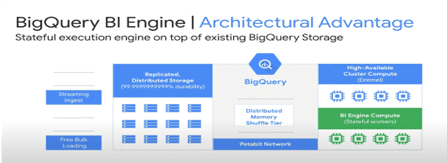
We see BI Engine is just another feature of BigQuery. So, it works on top of the same storage, same network, and same shuffle layer, and it runs alongside BigQuery workers.
Now the question arises: If everything is the same as BigQuery architecture, then what makes it possible for BI Engine to get such high-performance improvements? And this is exactly what we are going to learn today. So if you see in the above picture there are three pieces and all three of them contribute to the performance of the query.
- Storage is disk I/O time.
- Shuffle is a network I/O time.
- Compute is CPU.
Let’s pick each one of these three components and see how BI Engine reduces time to zero.
1. Memory Management
Starting with Memory Management which is the heart of BI Engine:
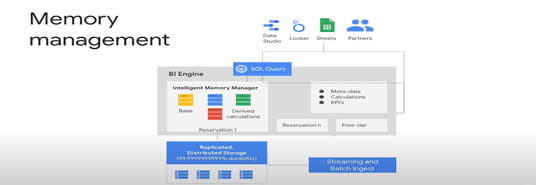 As we know BigQuery is a columnar database, so we put only specific columns into memory, not the whole table. Moreover, we are putting on only a chunk of the column, and that works equally well with both partitioned tables and non-partitioned tables. Here Memory Manager not only keeps raw data but also intermediate results of aggregations. It has very high integration with the metadata service, it knows exactly when the transaction commits. Also, memory managers know how to use load balancers, even if you have a small table but with lots of queries, it may choose to implicate the same data over multiple machines, which is easy for it to do because BigQuery is a distributed database. So, this way it will use small memory, but all of the queries will still have a very faster response time.
As we know BigQuery is a columnar database, so we put only specific columns into memory, not the whole table. Moreover, we are putting on only a chunk of the column, and that works equally well with both partitioned tables and non-partitioned tables. Here Memory Manager not only keeps raw data but also intermediate results of aggregations. It has very high integration with the metadata service, it knows exactly when the transaction commits. Also, memory managers know how to use load balancers, even if you have a small table but with lots of queries, it may choose to implicate the same data over multiple machines, which is easy for it to do because BigQuery is a distributed database. So, this way it will use small memory, but all of the queries will still have a very faster response time.
Now what kind of control users we have, this control comes in form of BI reservations which are very similar to classic BigQuery reservations but the currency is memory, so you are buying memory, not slots or CPU. All the metrics are served through Stackdriver.
The next component is the Compute Component, which uses vectorized processing and puts in the new runtime into BI Engine. So there are a lot of benefits for the CPU by using this concept, first, cache locality is much better as it runs on localized loops and second, code doesn’t jump around the operator to the operator which fills the CPU pipeline much tighter.
It also uses modern CPU instruction, which is SMG instructions that can process many values at the same clock time.
Also read: The Business Value of Data Virtualization with Denodo
2. Network Component
Now let’s move to another component which is the network.
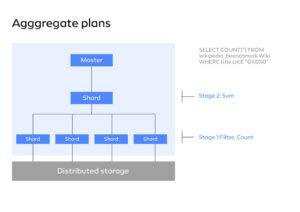
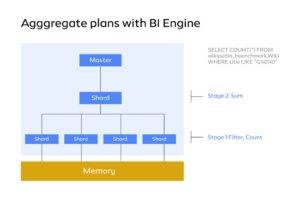
Look at a straightforward query that includes a count condition that internally uses the sum function as a kind of filter. It will compute the interim results and then distribute them across the networks. If you look closely at these images, you will see that they are identical. What makes them different, then? The answer is that a parallel plan is run rather than a distributed plan. As a result, network traffic is decreased.
Enabling BI Engine in GCP
Let’s create BI Engine Reservation:
Step 1: Visit Google Cloud Console. Search BI Engine
Step 2: Enable Big Query Reservation API
Step 3: Click ‘Create a Reservation’ to create Reservation
Step 4: Select Location, Allocate Memory
Step 5: (Optional) Select the Tables on which you want to run BI Engine
Step 6: Next, Create
Acceleration statistics in INFORMATION_SCHEMA
BI Engine acceleration statistics is queried as a part of INFORMATION_SCHEMA.JOBS_BY_* views through the col bi_engine_statistics. For example, below query will result all the bi-engine statistics.
select creation_time, job_id, bi_engine_statistics
from `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
where creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) AND CURRENT_TIMESTAMP()
and job_type = “QUERY”
Want to know more about our BigQuery and BI Engine services.
Click here
Conclusion
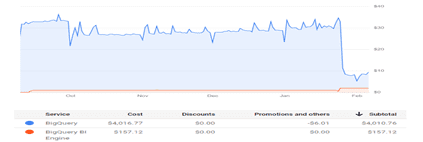
In this blog, we went through the impact of the BI Engine on cost and execution time. BI Engine is an important service that addresses the above challenges and what we see as the benefit of cost reduction is 50% and execution time reduction is 80%.